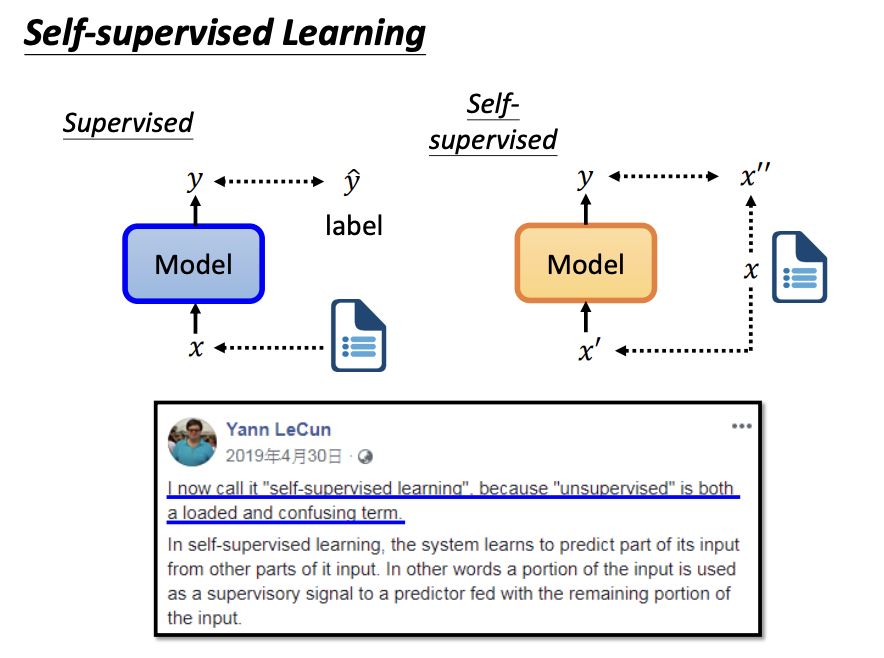
Compared to supervised learning, which requires both input data and labels, unsupervised learning, as its name suggests, only requires input data. Among various unsupervised learning paradigms, self-supervised learning is one of the most prominent approaches.
BERT
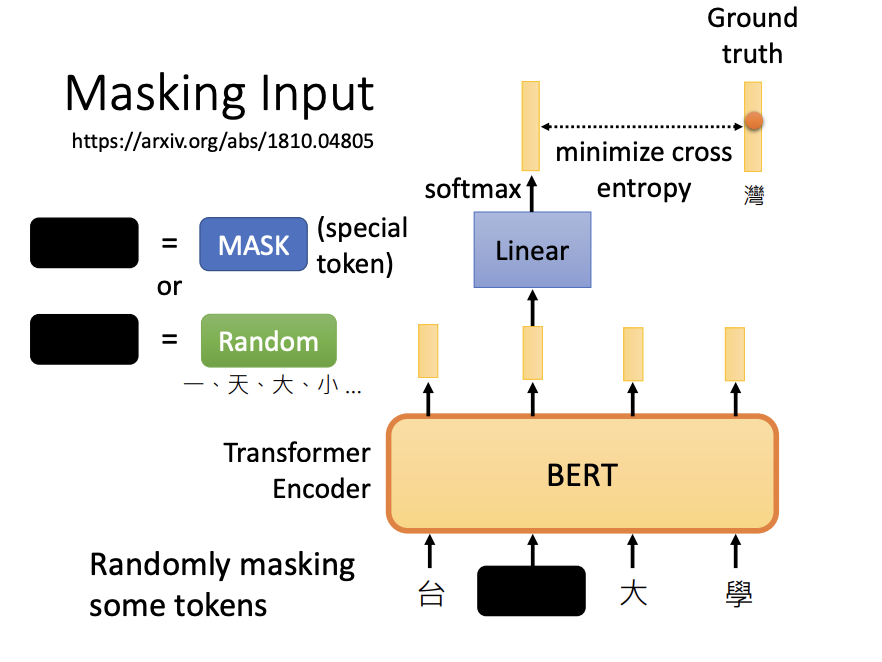
BERT is one of the most well-known self-supervised learning models and operates primarily as a sequence-to-sequence model. The core training objectives of BERT are:
- Masked token prediction
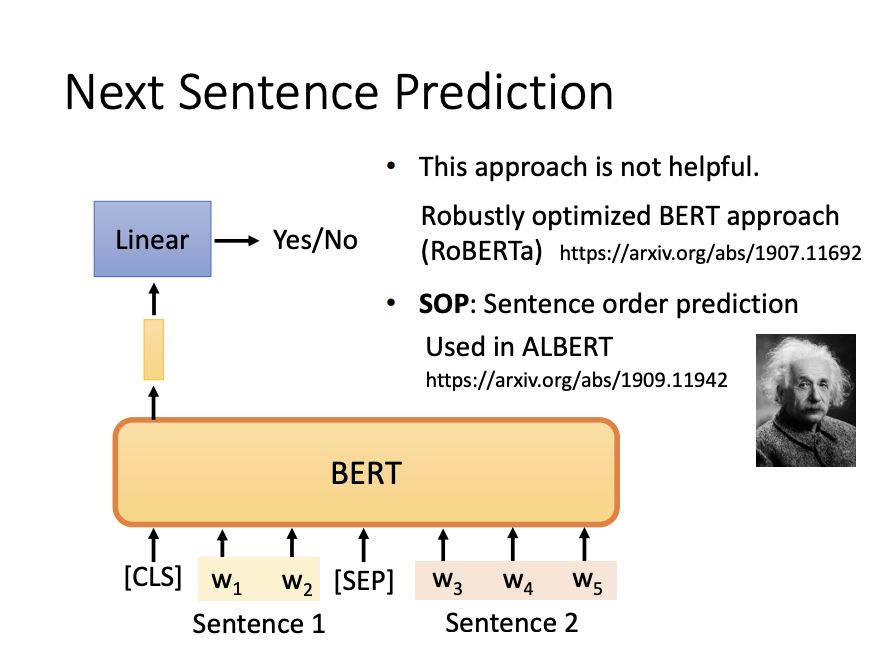
- Next sentence prediction
Masked token prediction involves masking or replacing specific tokens in the input sequence. The model then learns to predict the original sequence, effectively reconstructing the masked elements.
Next sentence prediction, on the other hand, requires the model to determine whether a given sentence logically follows another sentence in a pair.
What can BERT do?
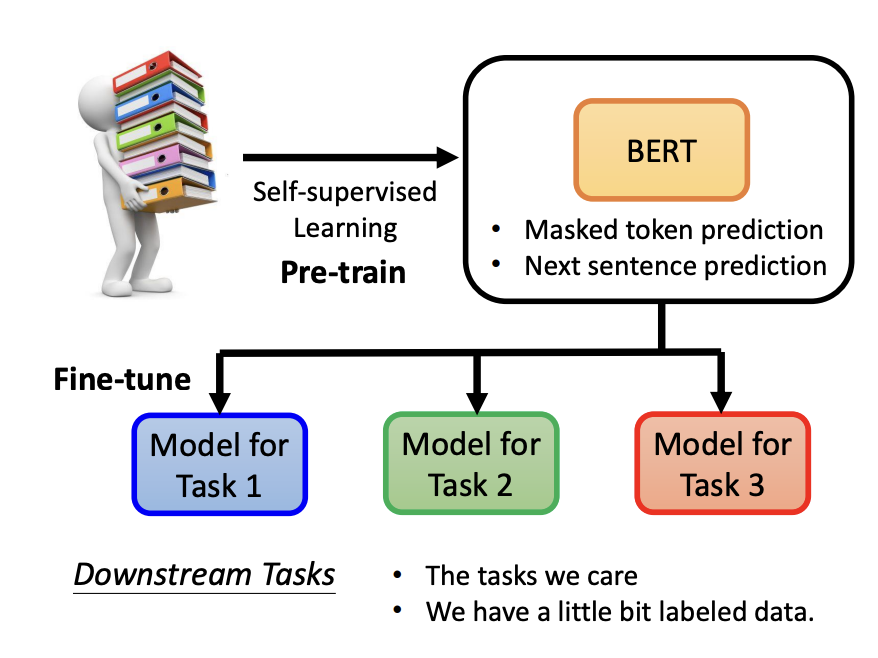
The transformative power of BERT lies in its ability to serve as a foundation for various downstream tasks—specific applications we care about in natural language processing (NLP). This involves a two-stage process:
- Pre-training: BERT is trained on large-scale unlabeled data using self-supervised objectives.
- Fine-tuning: The pre-trained model is further trained on labeled datasets tailored for specific downstream tasks, thereby adapting BERT to new domains.
Applications of BERT:
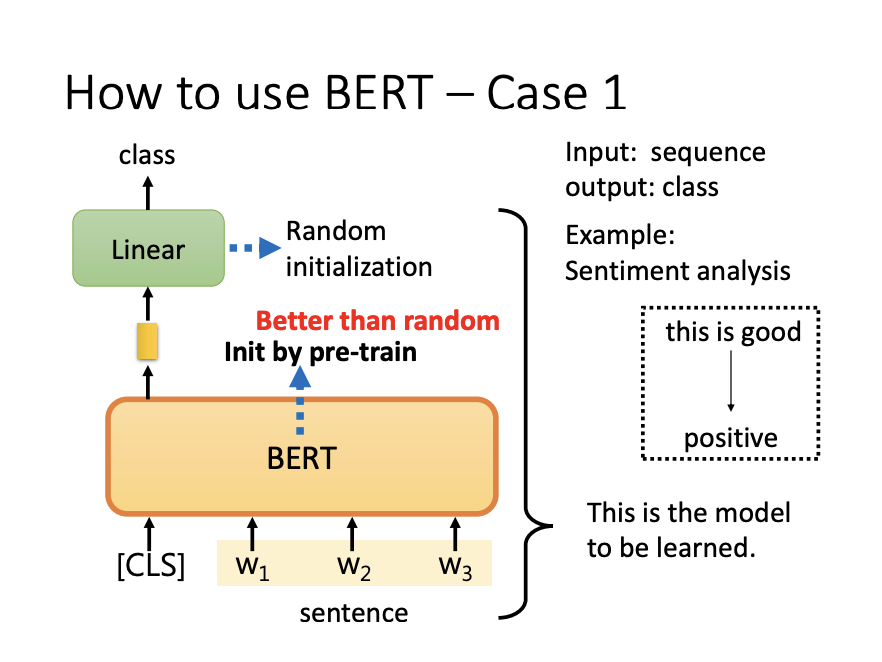
- Sentiment Analysis:
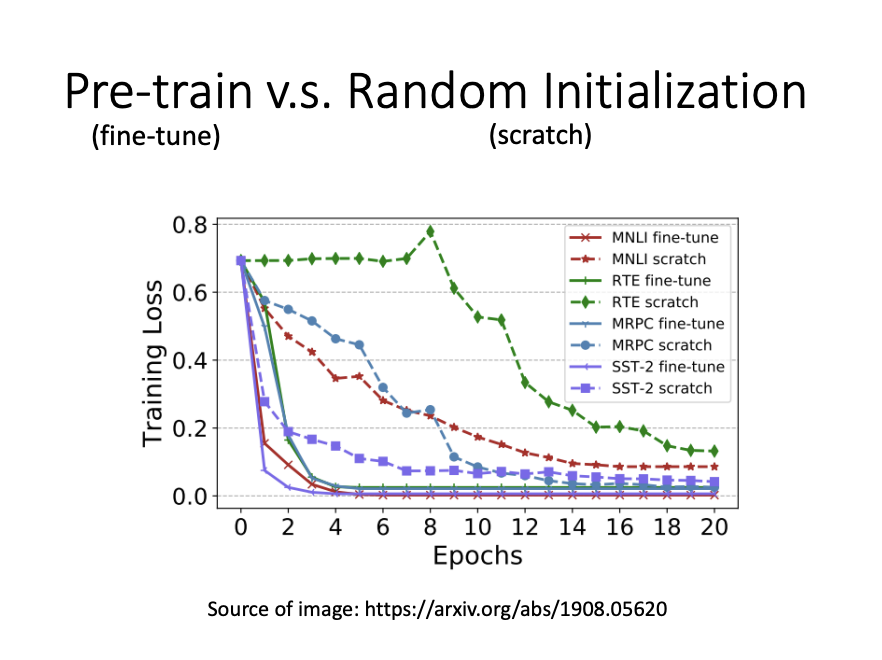
A sentiment classifier can be built using a pre-trained BERT model. By fine-tuning BERT with labeled sentiment data, the model learns to classify sentiment effectively. Pre-trained BERT models typically outperform randomly initialized models due to their lower initial loss and superior convergence rates.
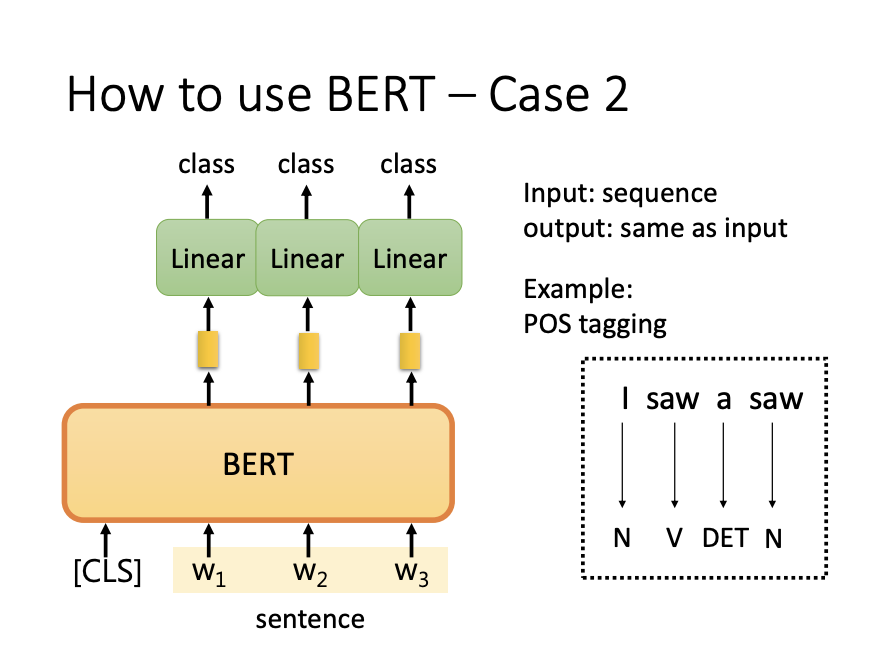
- Part-of-Speech (POS) Tagging:
BERT can also handle tasks requiring token-level predictions, such as POS tagging. In this case, a pre-trained BERT model is fine-tuned with labeled data to produce sequence outputs matching the input sequence length, enabling accurate POS tagging.
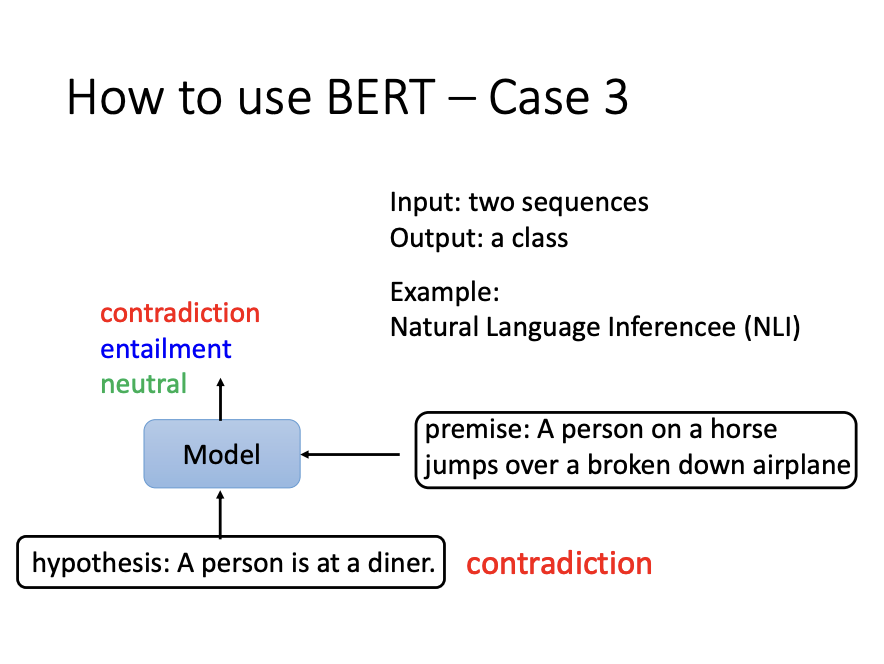
- Natural Language Inference (NLI):
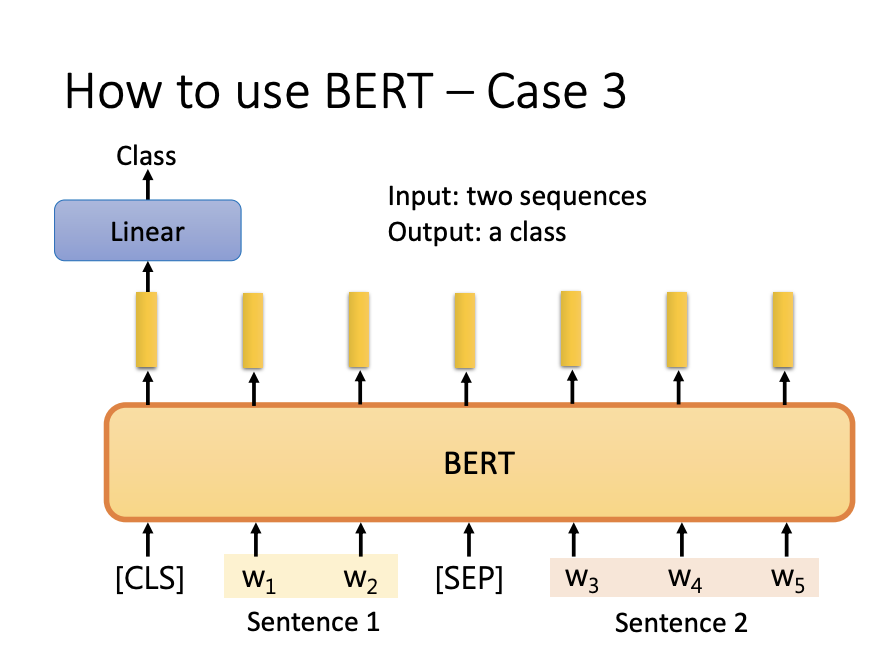
BERT is frequently used for NLI tasks, which involve determining the relationship between two sentences. For example, the model classifies whether the second sentence is a contradiction, entailment, or neutral relative to the first.
- Extraction-Based Question Answering:
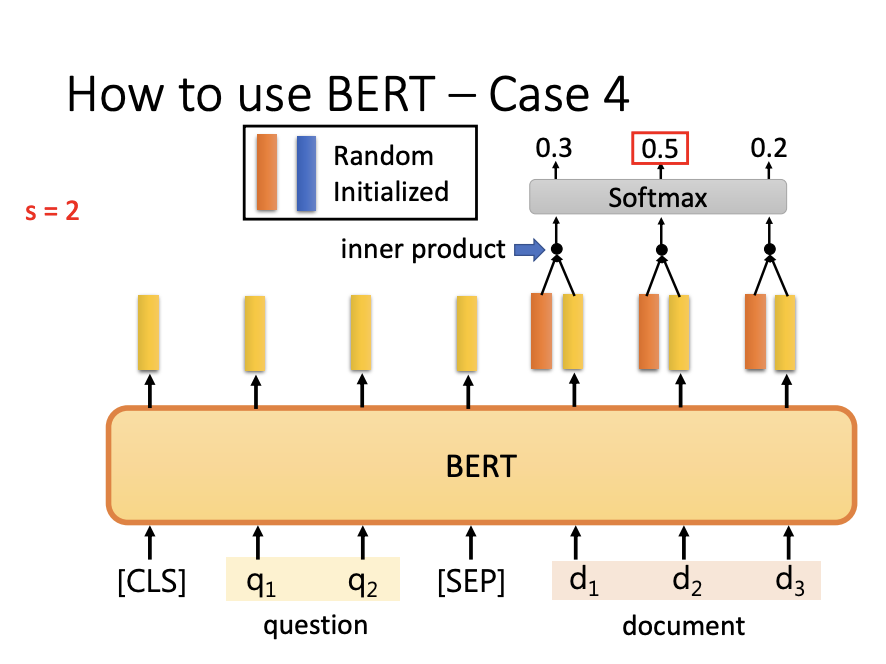
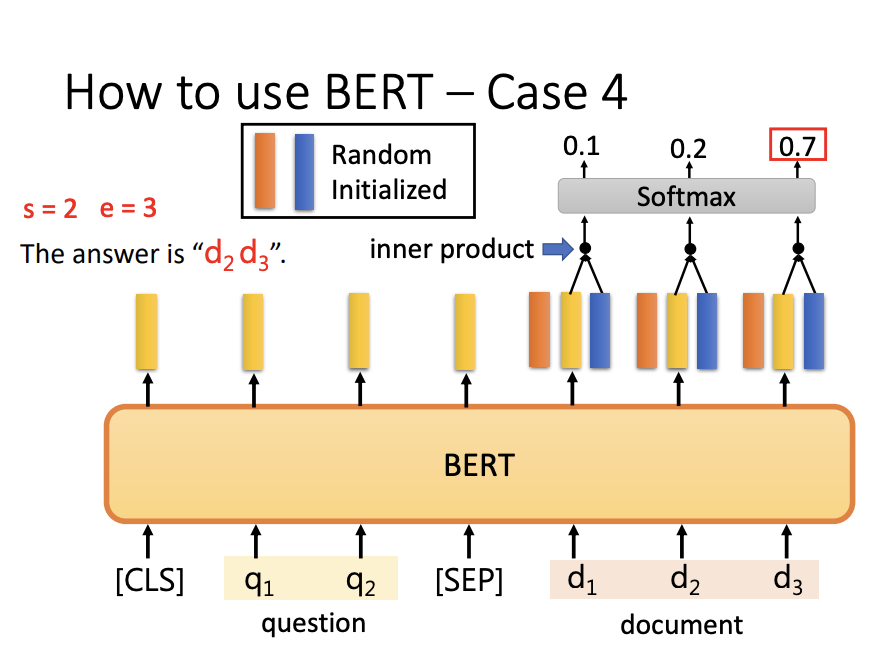
BERT is widely employed for extraction-based question answering. The process involves inputting a document sequence and a question sequence, and the model outputs two integers representing the start and end positions of the answer within the document. Two randomly initialized vectors are used to compute these positions. Each vector interacts with the output sequence from BERT, followed by a softmax operation to identify the positions with the highest confidence.
Why Does BERT work?
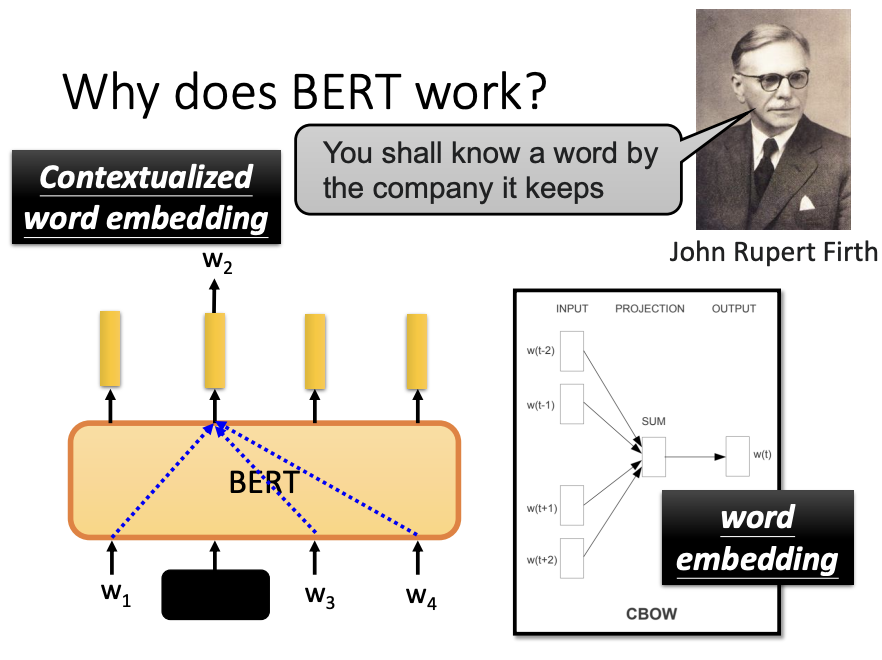
In linguistics, there is a well-established principle that the meaning of a word is determined by its surrounding context, often summarized as “the company it keeps.” BERT leverages this idea during training. By masking or replacing certain words and predicting them based on the surrounding context, BERT learns to extract contextual information effectively, enabling it to understand word meanings and relationships.
GPT
In addition to BERT, GPT is another influential self-supervised learning model. Unlike BERT, which focuses on bidirectional context, GPT generates the next token based on the preceding input tokens, making it a unidirectional model.
GPT differs from BERT in its approach to task adaptation. While BERT relies on fine-tuning for specific tasks, GPT employs in-context learning methods such as few-shot, one-shot, or zero-shot learning. This flexibility allows GPT to perform tasks with minimal or no additional training.
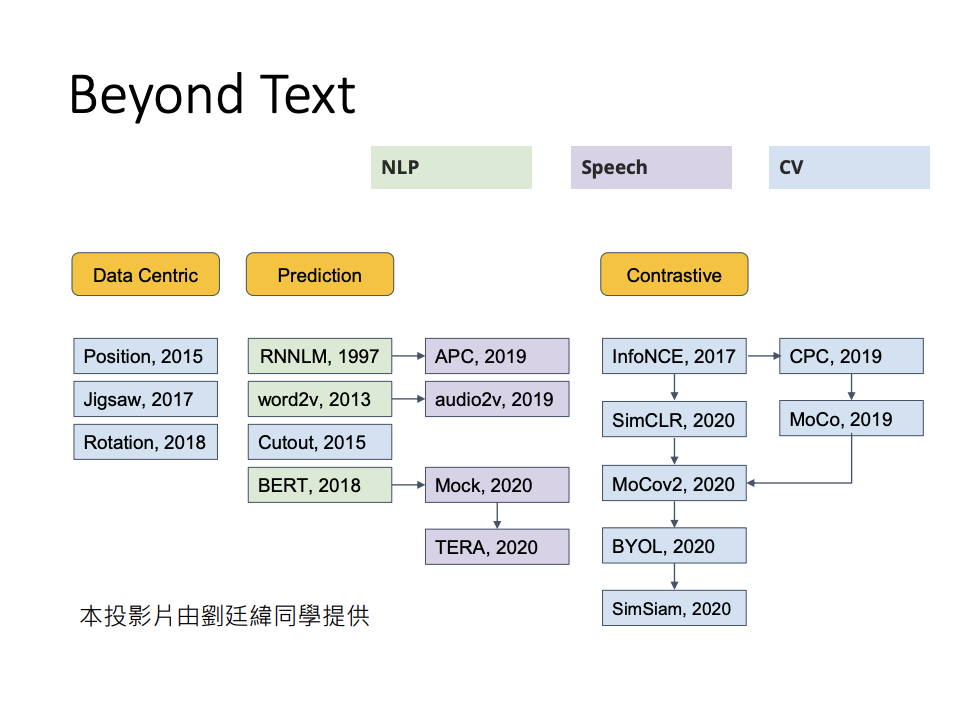
Self-supervised Learning Beyond Text
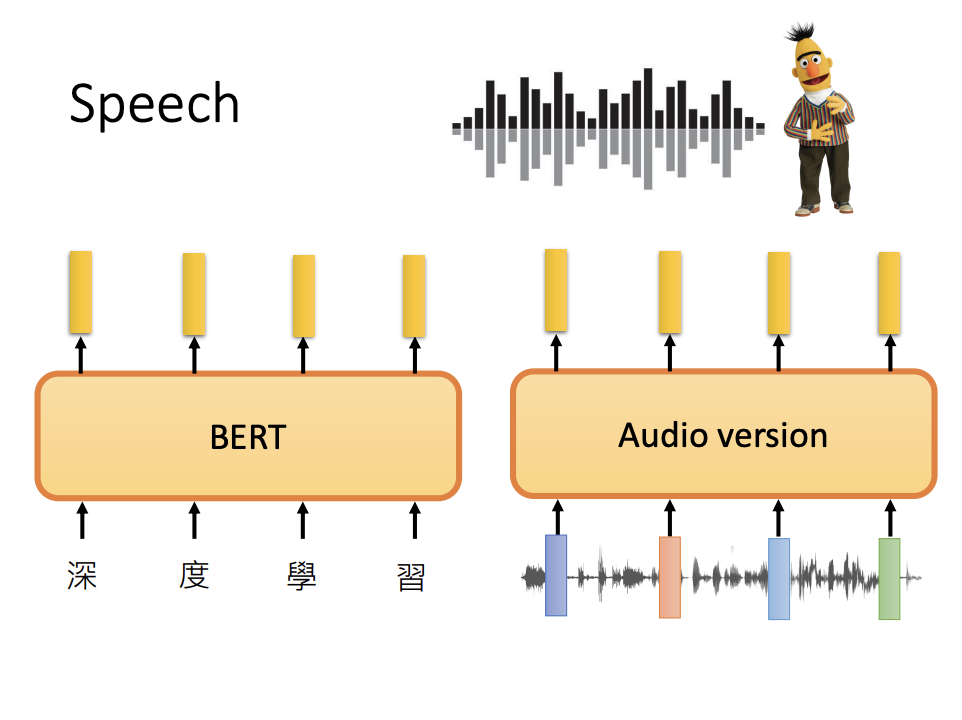
Self-supervised learning is not limited to text-based applications. It extends to other domains such as natural language processing (NLP), speech processing, and computer vision (CV), where it continues to demonstrate remarkable potential in learning from unlabeled data.
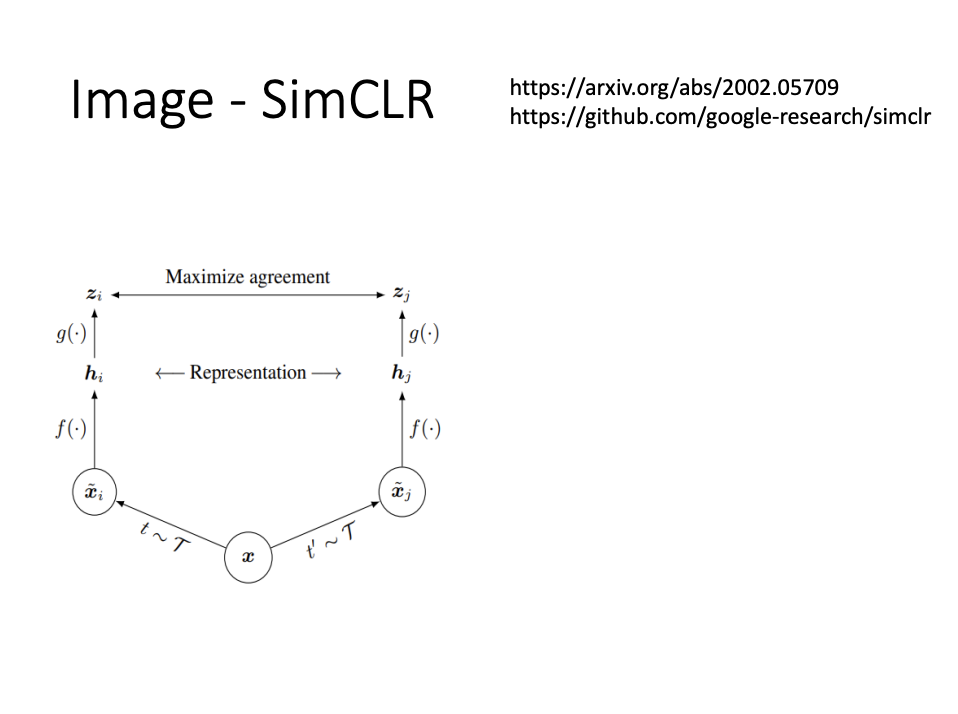
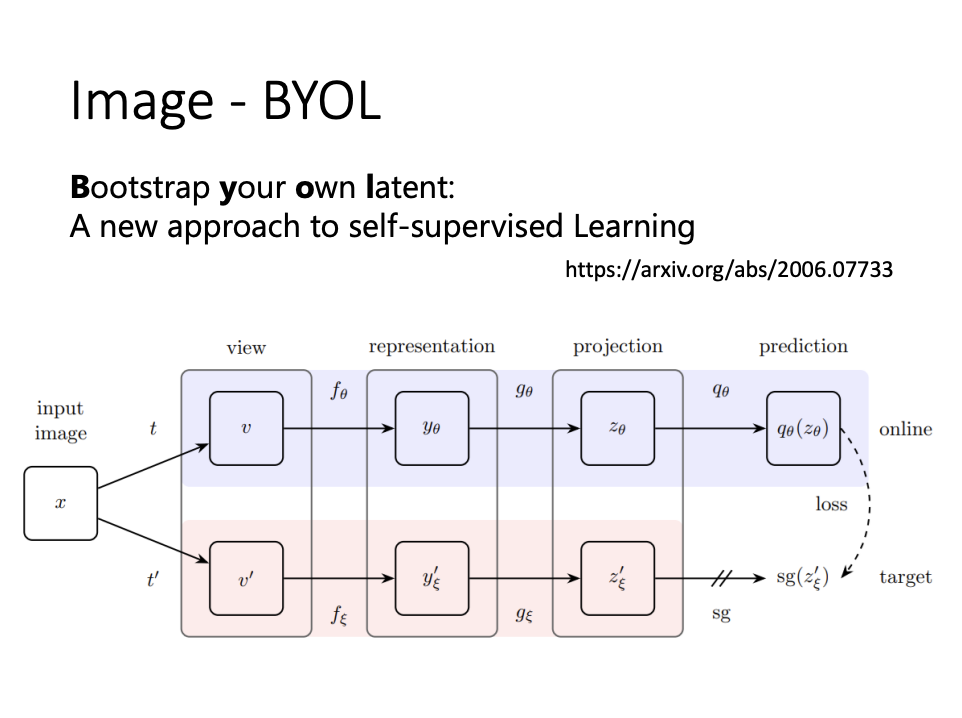
Image
Speech
![[ML]Self-supervised Learning](/assets/images/2024-11-12-self-supervised-learning/2024-11-21-00-46-08.png)