![[ML][CNN]Convolutional Neural Networks](/assets/images/2024-09-26-convolutional_neural_networks/2024-10-16-21-44-34.png)

[ML][CNN]Convolutional Neural Networks
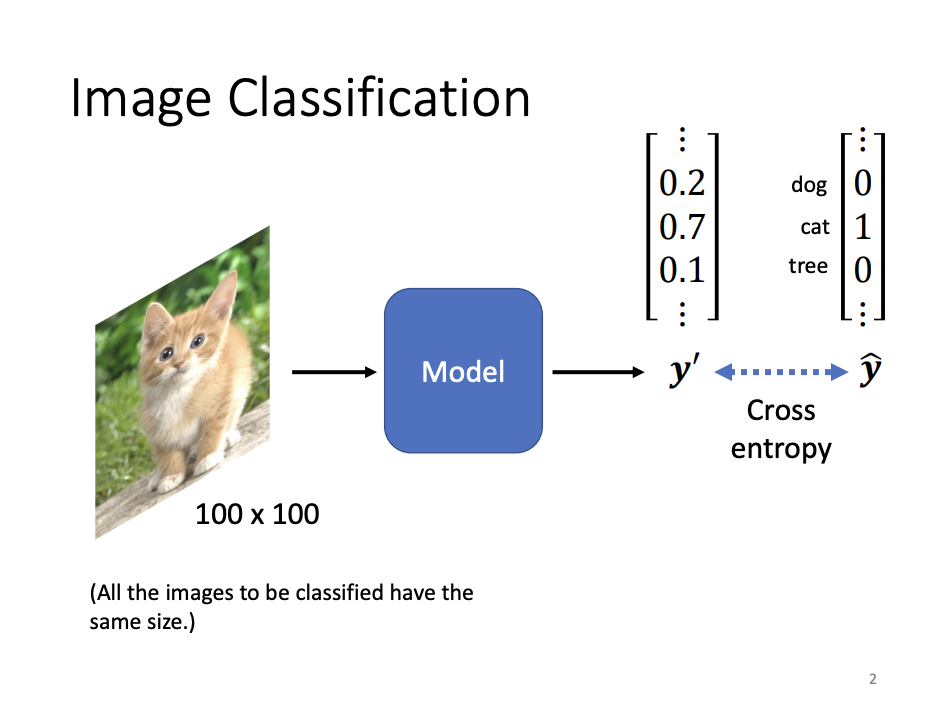
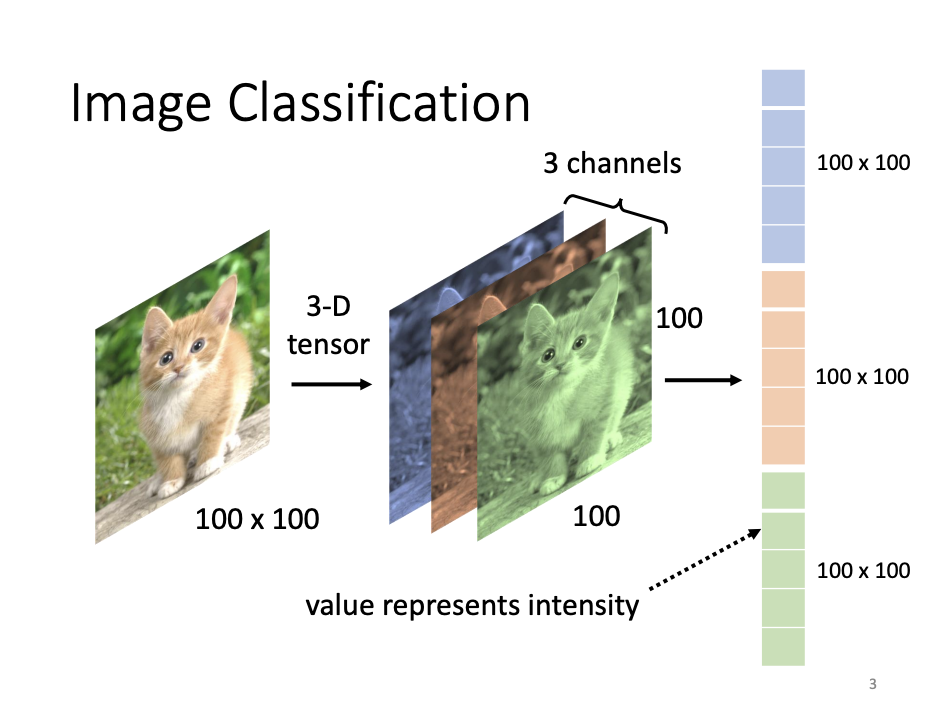
There are numerous network architectures tailored for specific tasks, and Convolutional Neural Networks (CNNs) represent a prominent class, specifically designed for image processing based on domain knowledge. In the context of image classification, CNNs are capable of discerning the contents of an image. To achieve this, CNNs decompose an image into three-dimensional tensors, corresponding to the RGB color channels, convert these tensors into one-hot encoded vectors, and then feed them into the network.
 |
 |
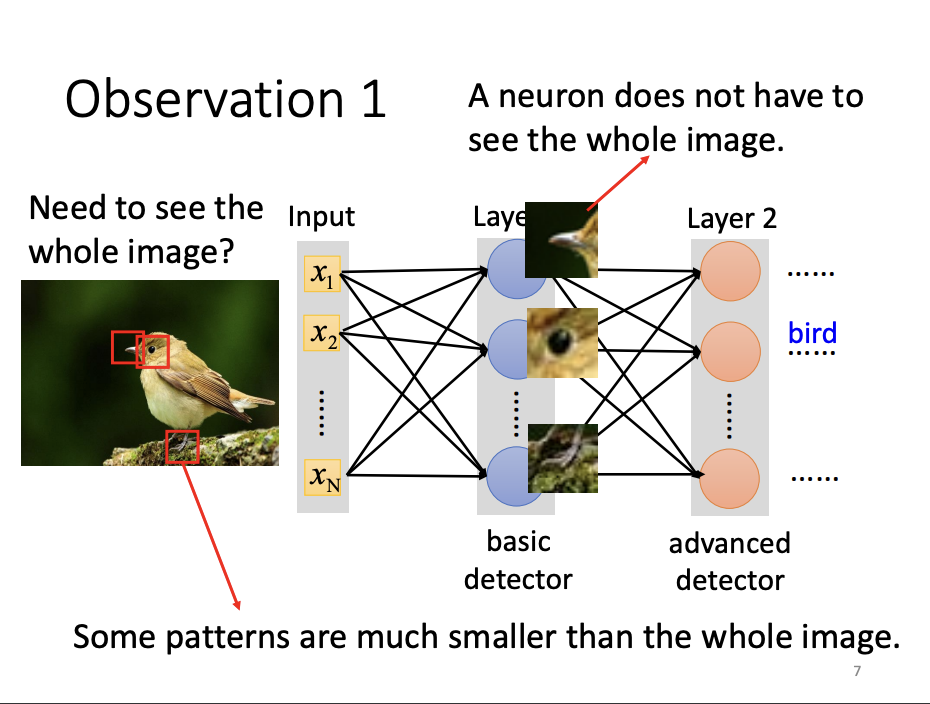
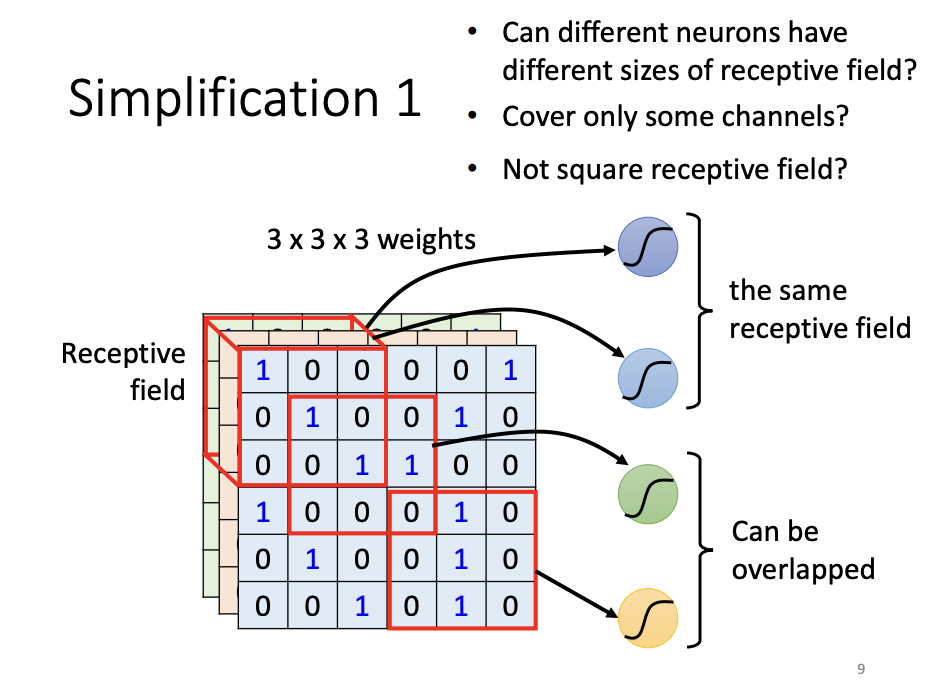
Receptive Field
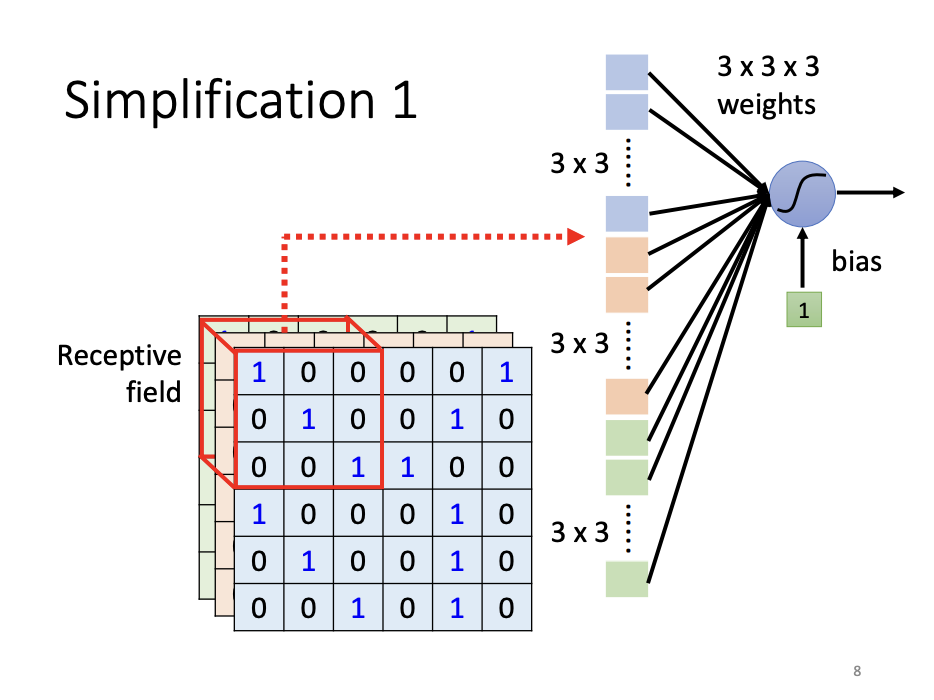
In human vision, when identifying a bird in an image, we often rely on specific visual features, such as the beak, eyes, or claws, drawing on our domain knowledge to focus on relevant regions of the image. Similarly, in machine learning, there is no need for each neuron to analyze the entire image, as would be the case in a fully connected network. Instead, CNNs introduce the concept of a receptive field, where each neuron is responsible for a specific portion of the image. This localized focus allows the network to detect patterns in discrete regions. To ensure comprehensive image analysis, the receptive fields of all neurons collectively span the entire image.
 |
 |
 |
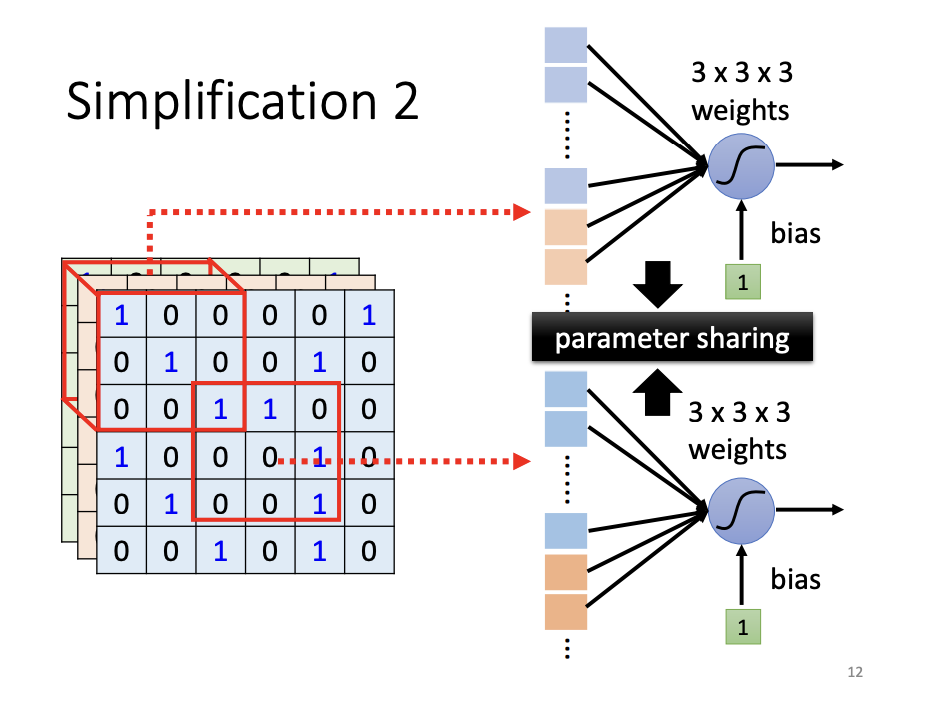
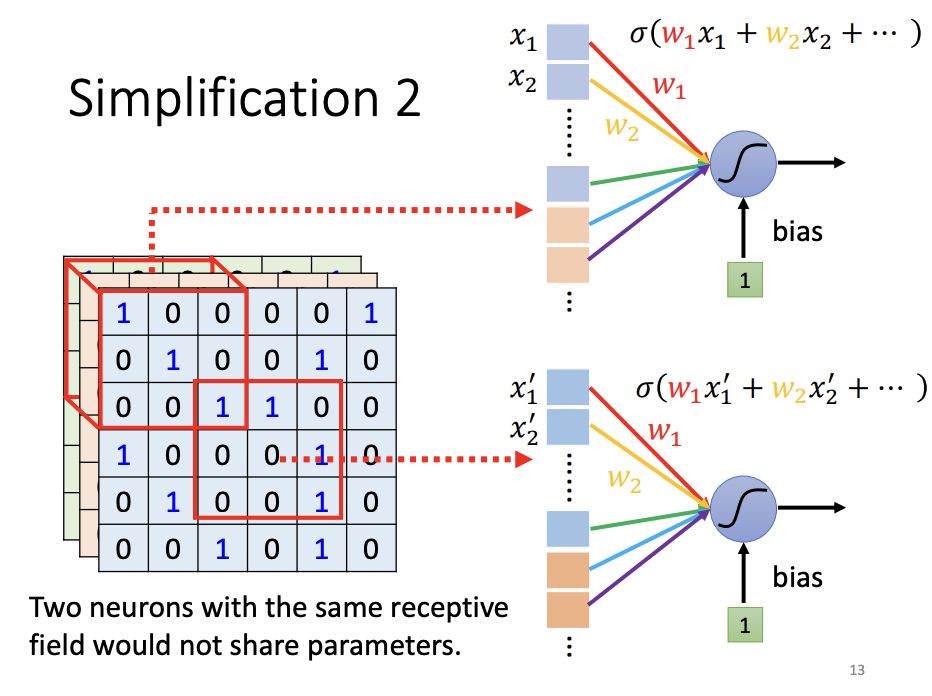
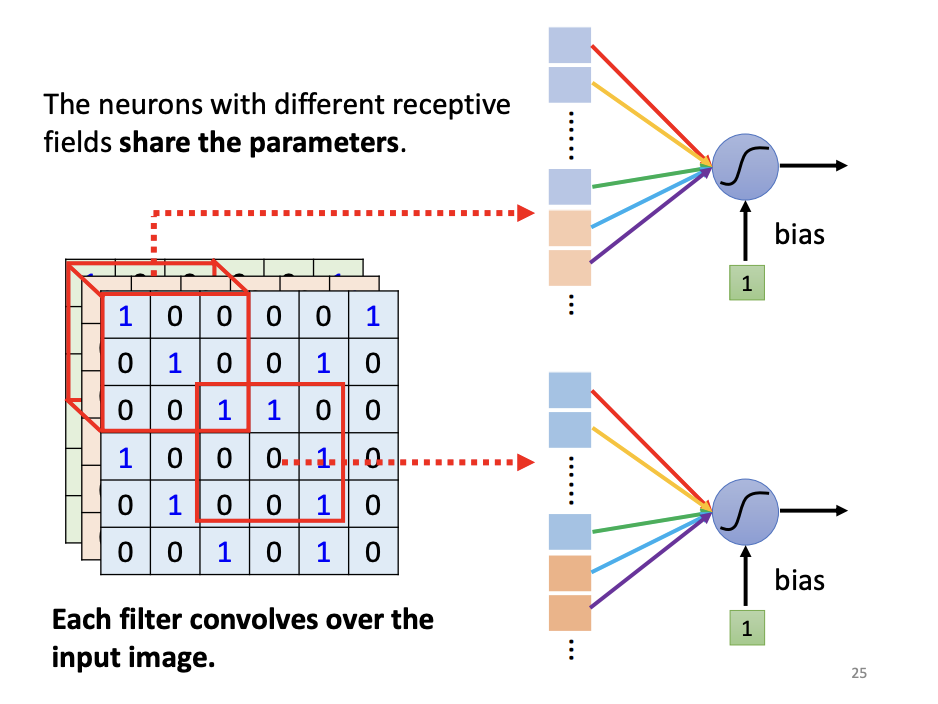
Parameter Sharing
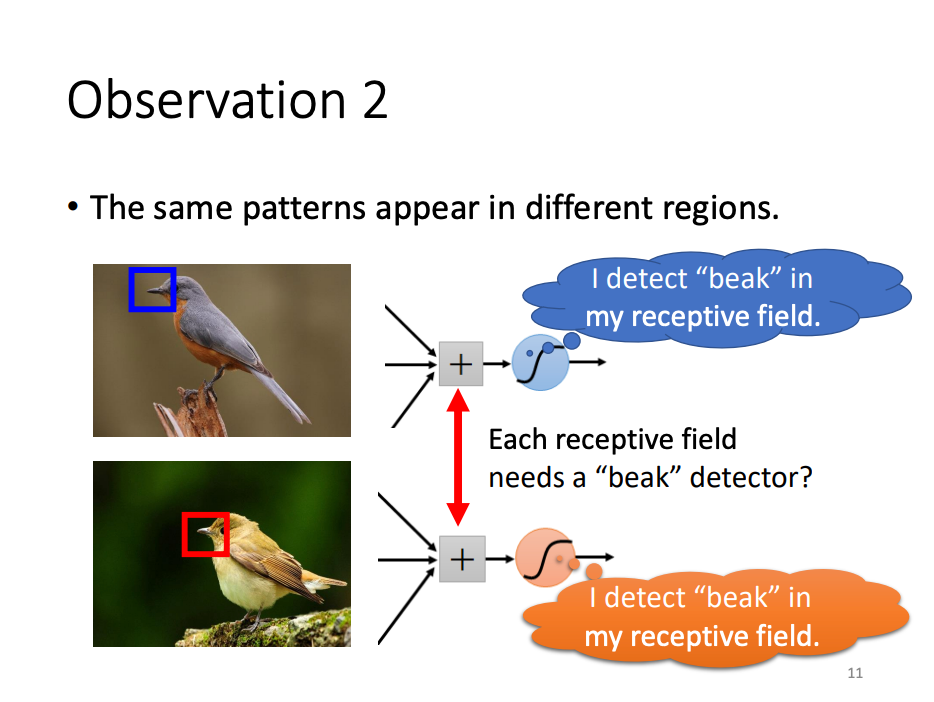
Patterns within an image often recur across different receptive fields. In such cases, it would be redundant to use distinct neurons to detect the same pattern across different regions. To address this, CNNs utilize parameter sharing, allowing neurons to share the same parameters when detecting similar patterns. This mechanism enables a single neuron to apply the same set of parameters across multiple receptive fields, improving efficiency and reducing the complexity of the model.
 |
 |
 |
Convolutional Neural Network(CNN)
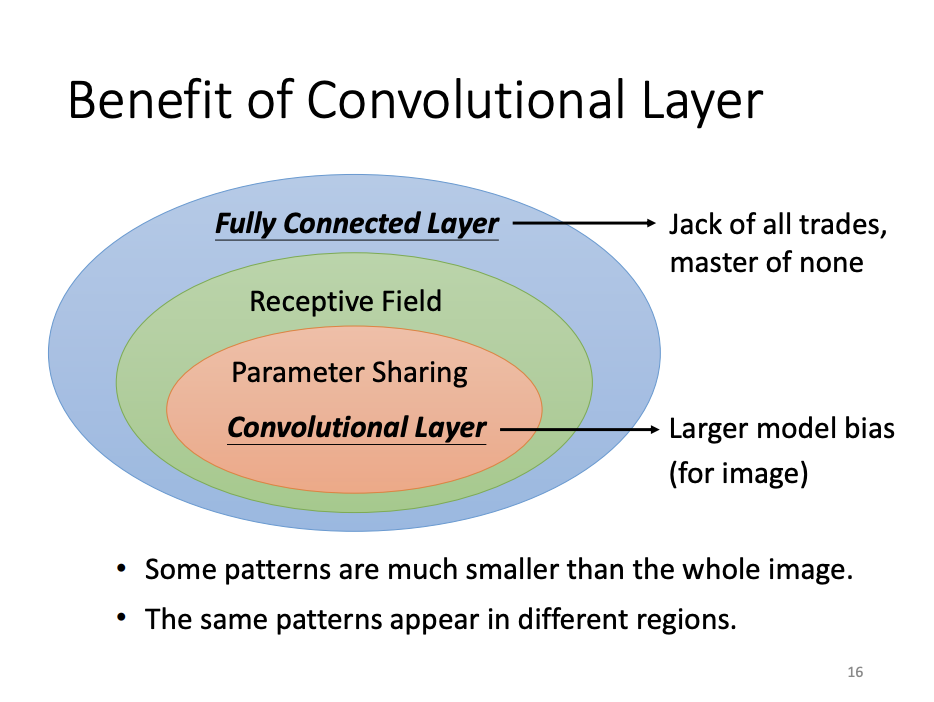
In essence, CNNs are built upon the principles of receptive fields and parameter sharing. As we move from fully connected layers to convolutional layers, flexibility decreases while model bias increases. However, this increase in bias is not inherently detrimental, as fully connected layers are more prone to overfitting, which can lead to artificially high training scores. CNNs, on the other hand, are optimized for image-related tasks, and despite the increase in bias, their performance remains robust due to domain-specific optimizations.
 |
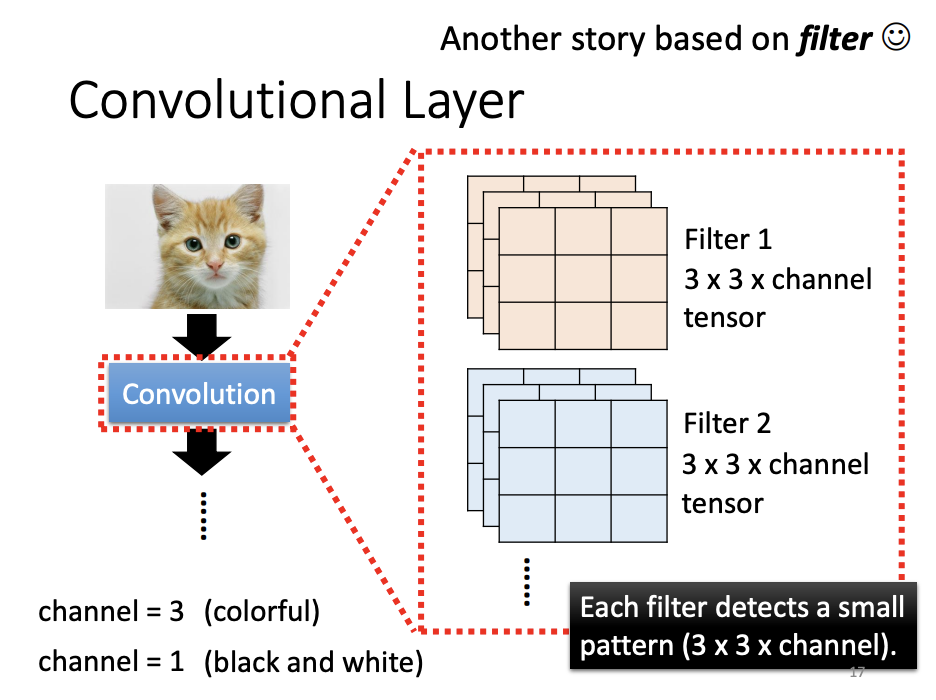
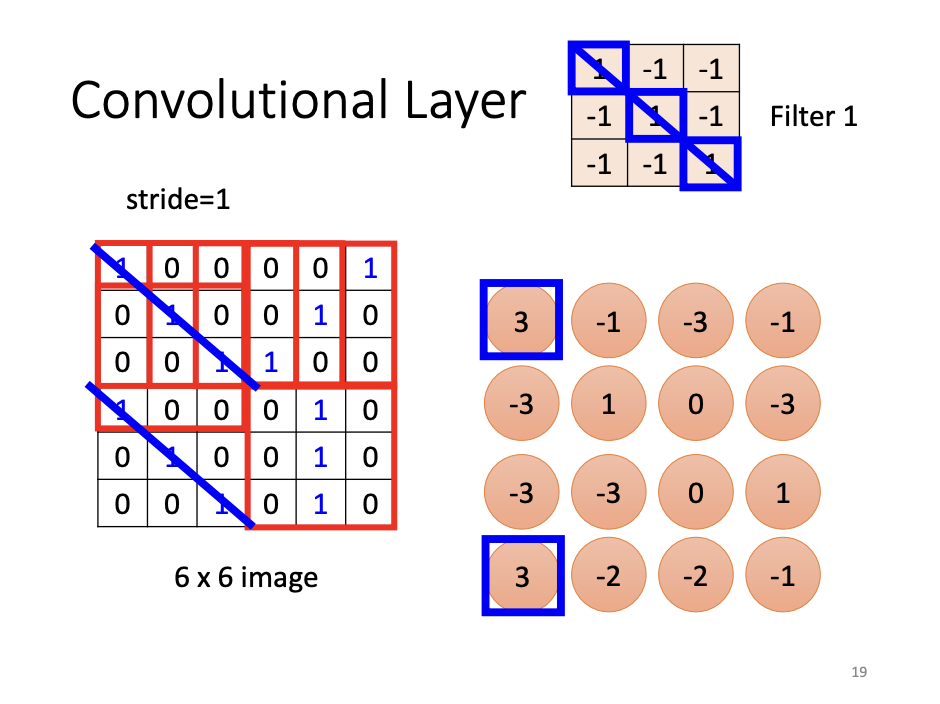
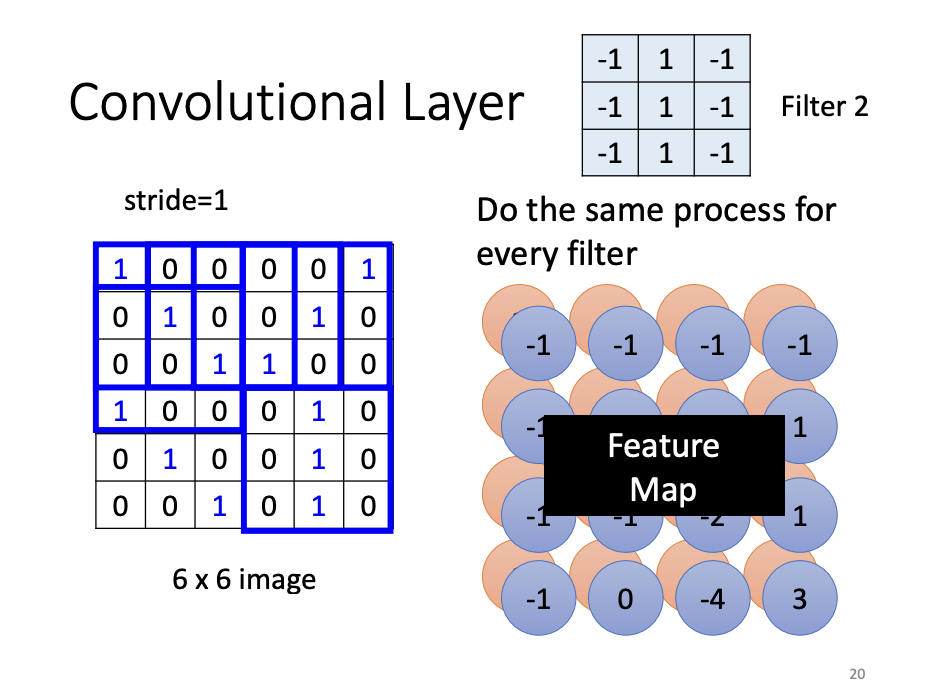
Another perspective for understanding CNNs is through the concept of filters. When processing an image, multiple convolutional layers are applied, each containing numerous filters. The values within these filters represent parameters that are learned during the training process. As each filter scans the image incrementally (stride by stride), it produces a feature map, which serves as the input for subsequent convolutional layers. The feature map can be interpreted as an intermediate representation of the image at each stage of the network.
 |
 |
 |
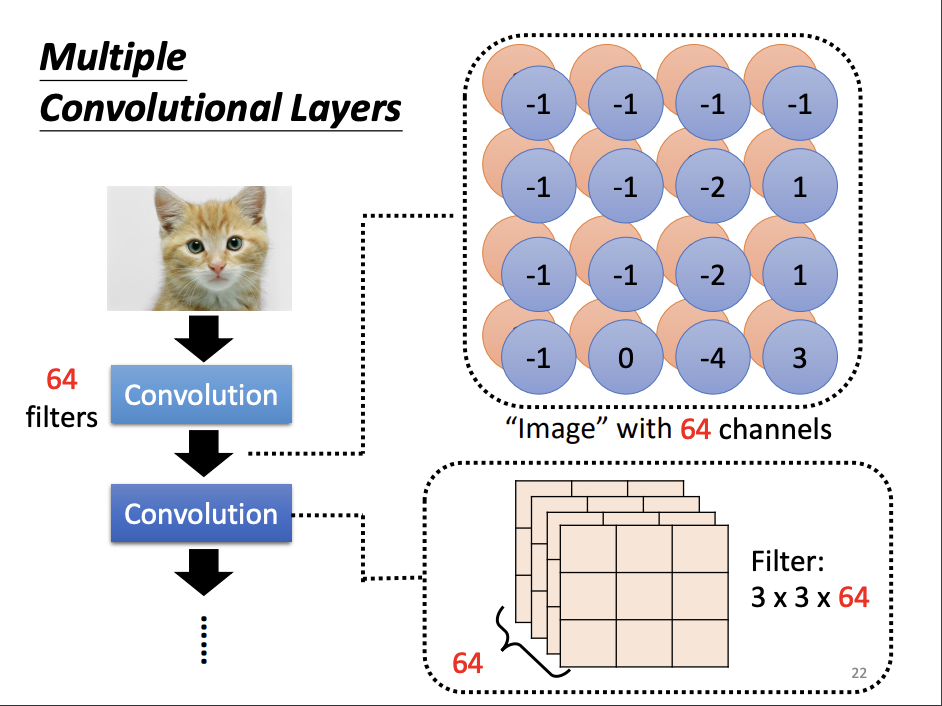 |
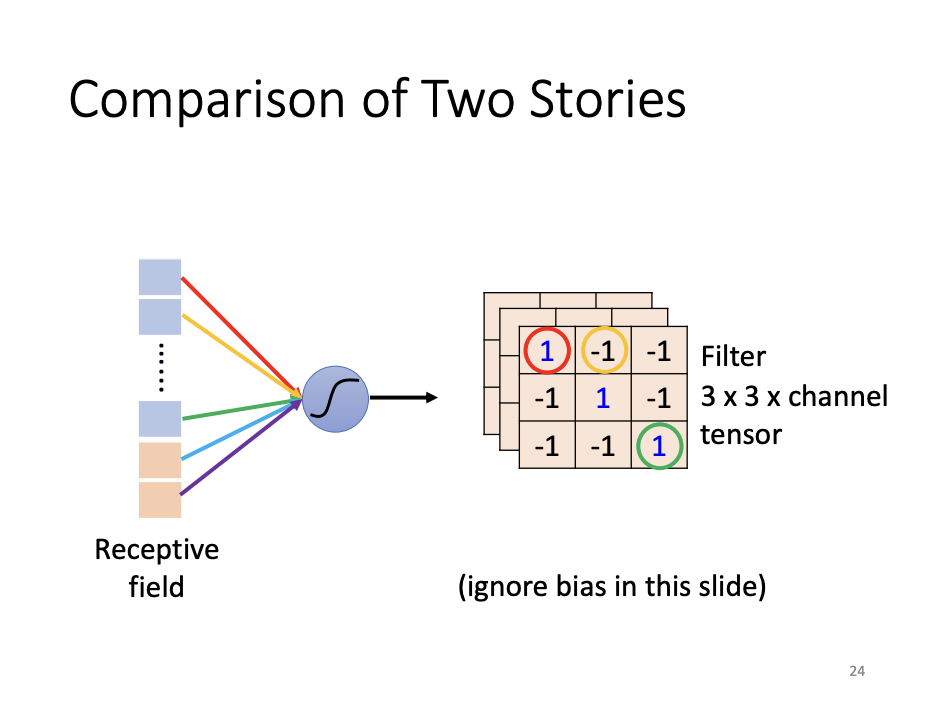
From both perspectives, the unknown parameters within the filters are analogous to the weights and biases of neurons. Parameter sharing, in turn, is functionally equivalent to the process of filters scanning the image, which is the core operation of convolution.
 |
 |
 |
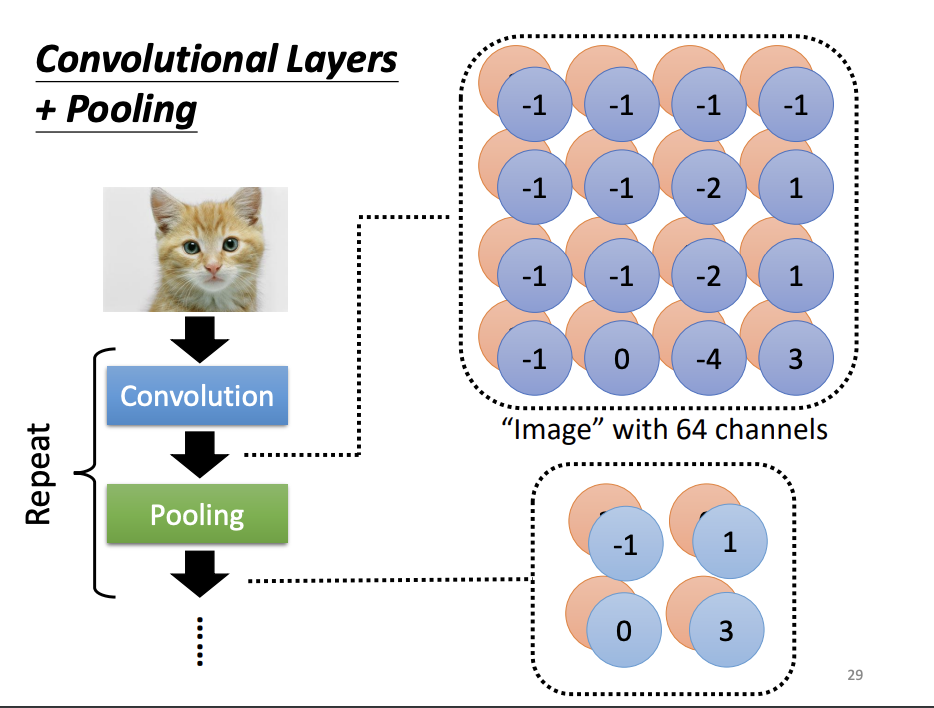
Pooling
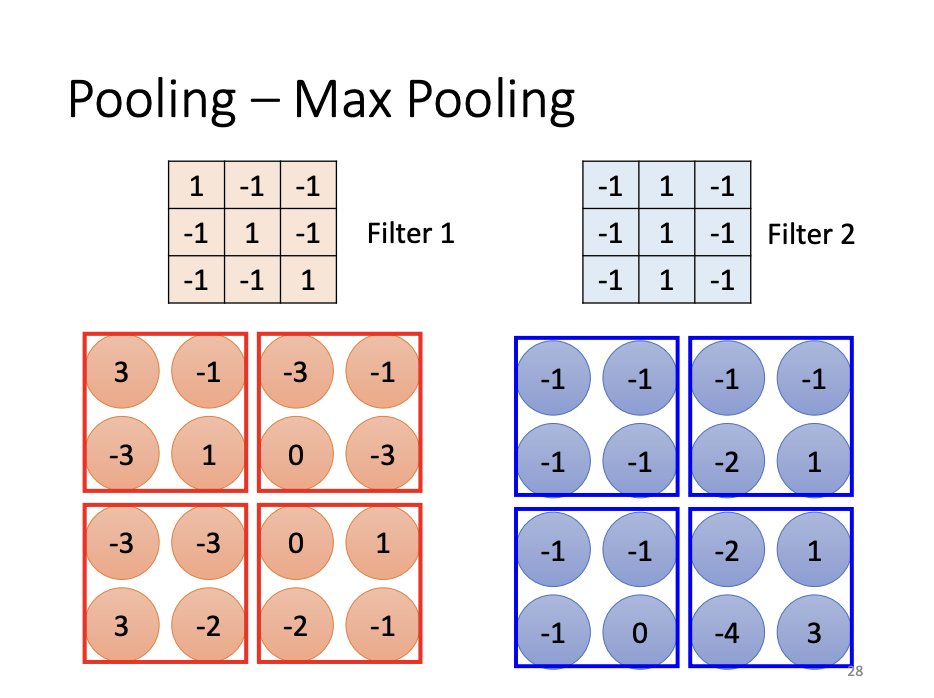
Pooling is another crucial operation in CNNs, introduced to reduce the spatial dimensions of feature maps while retaining critical information. The principle behind pooling is that subsampling an image does not significantly alter the presence of key objects. Max pooling, for example, selects the maximum value within a group of pixels, thereby reducing the size of the feature map and, consequently, the computational burden. Pooling operations typically follow convolutional layers to further streamline the processing pipeline.
 |
 |
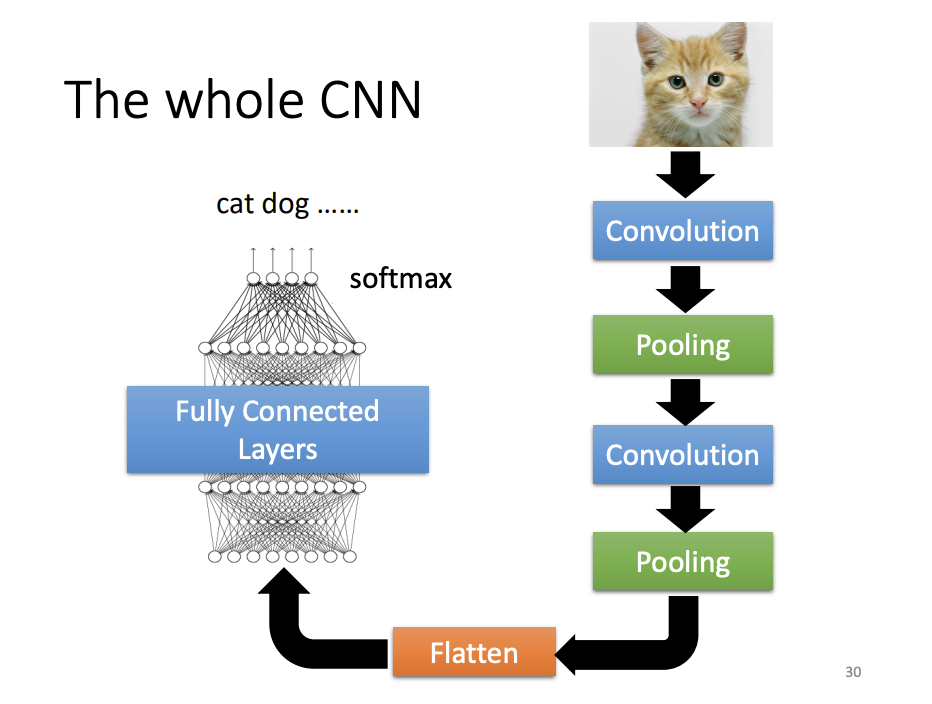 |
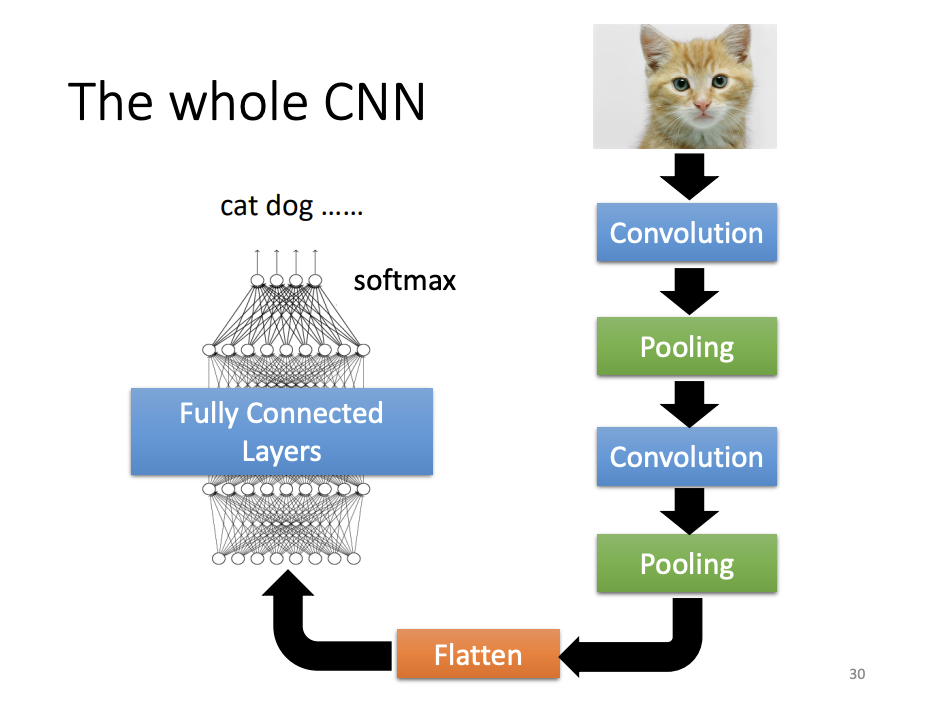
The Complete CNN Pipeline
After multiple convolution and pooling operations, the feature maps are flattened into vectors, which are then passed through fully connected layers. Finally, a softmax function is applied to produce the final classification output.
 |
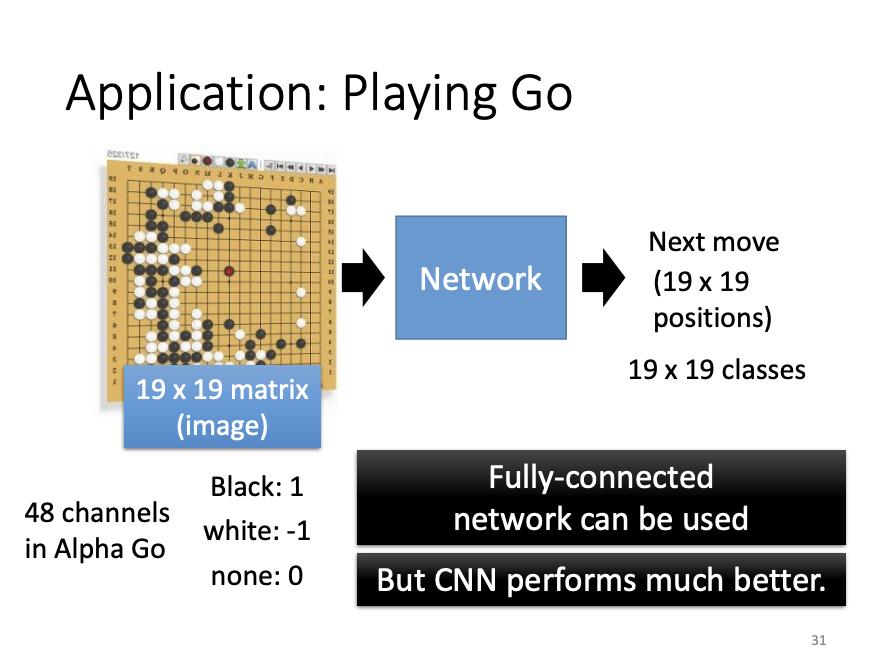
AlphaGo: CNN Applications Beyond Image Recognition
In addition to image recognition, CNNs have proven effective in tasks such as playing the board game Go, as demonstrated by AlphaGo. Each state of the Go board can be represented as a vector and fed into the network, where the prediction of the next move becomes a classification task. While fully connected networks could be applied to this problem, CNNs have demonstrated superior performance by treating the board as a grid, akin to a two-dimensional image (rows and columns). Two key factors contribute to the efficacy of CNNs in this context:
- The game of Go relies heavily on local patterns, which are often much smaller than the entire board.
- These patterns can appear in different regions of the board, and CNNs are adept at recognizing such recurring structures. One notable difference in applying CNNs to Go is that pooling is not used. This is because every row and column on the Go board is significant, and reducing the dimensionality through pooling would risk losing critical spatial information.
 |
 |
 |