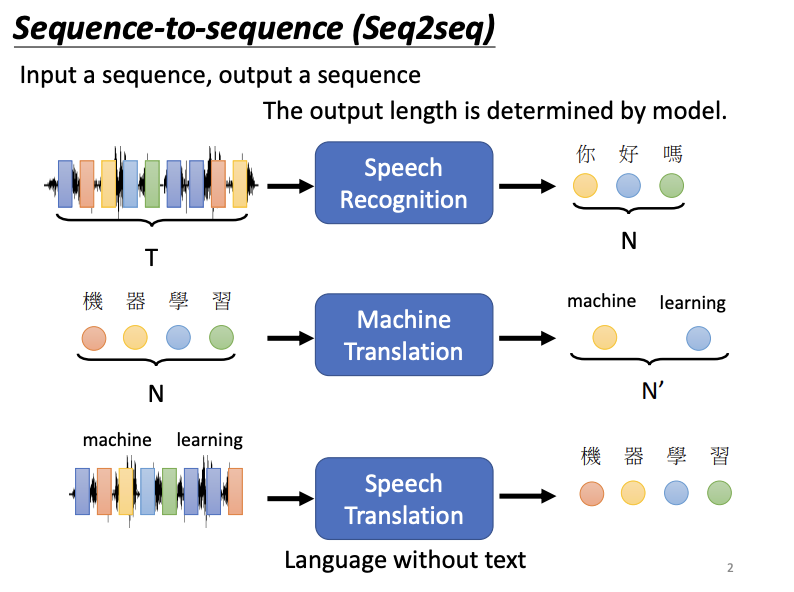
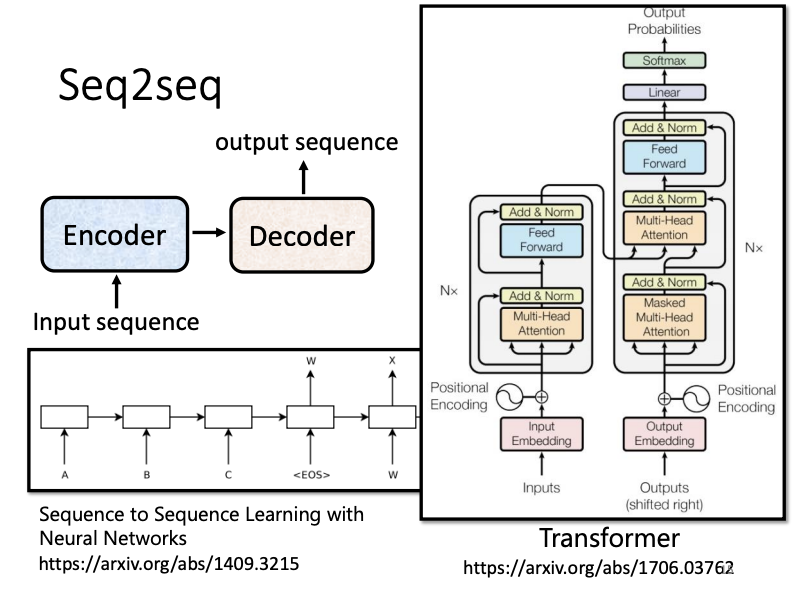
In sequence-to-sequence (Seq2seq) problems, the model takes an input sequence and generates an output sequence, with the length of the output being determined by the model itself. This approach is central to tasks like speech recognition, machine translation, and speech-to-speech translation, and is even applicable to conversational AI or chatbot systems.
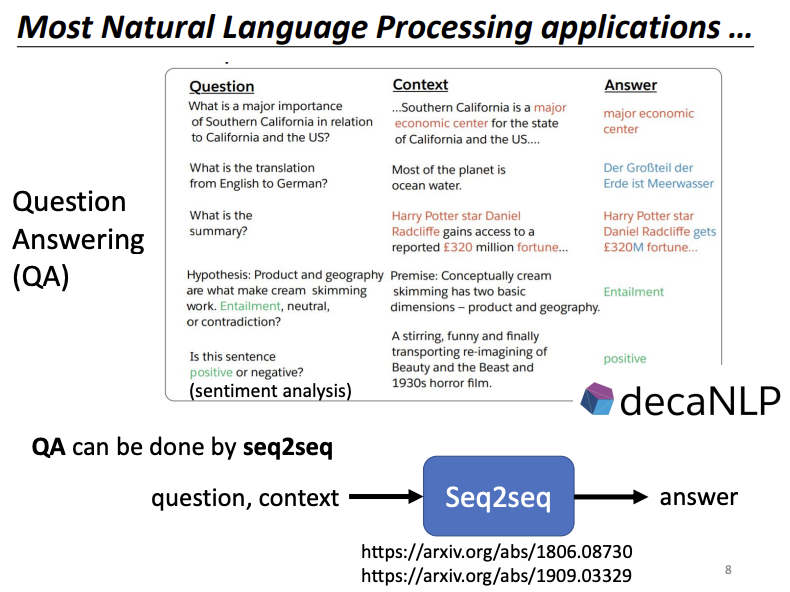
Most applications in natural language processing (NLP) can be framed as question-answering tasks. For example, translation can be seen as answering the question, “What is the translation of this sentence?” Similarly, text summarization can be framed as, “What is the summary of this article?” and sentiment analysis as “Is this sentence positive or negative?” While Seq2seq models offer a generalized approach to question-answering tasks, models optimized with domain-specific knowledge often outperform standard Seq2seq models in practical applications.
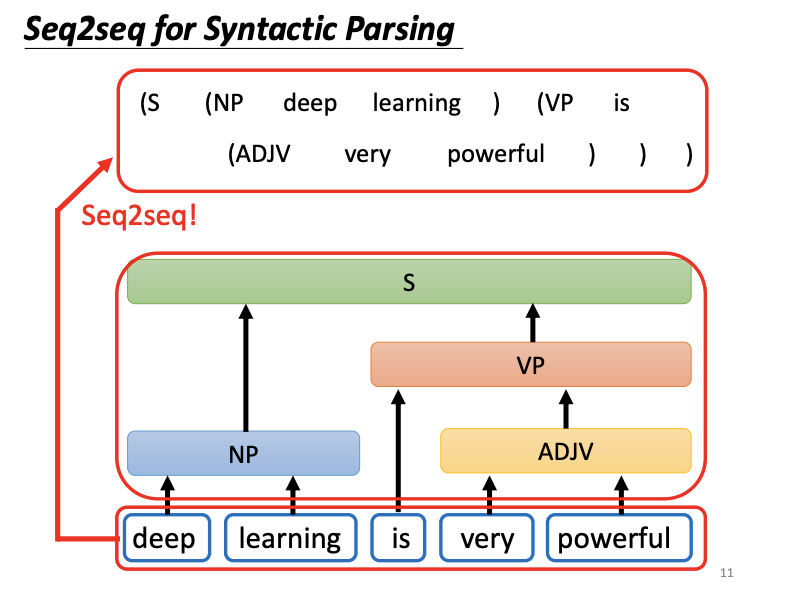
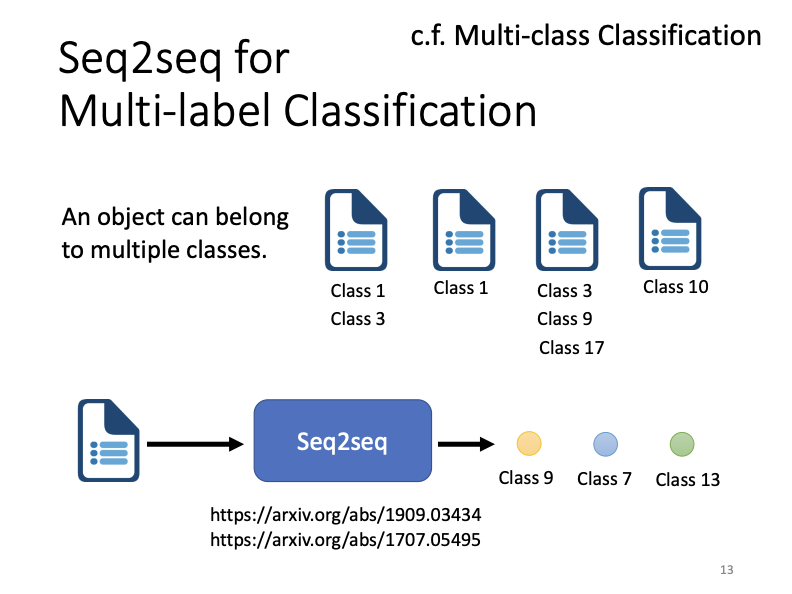
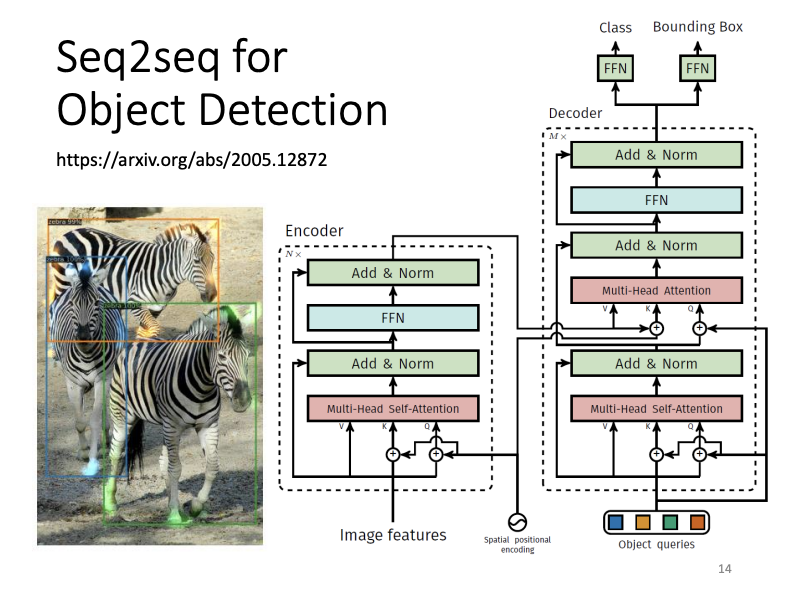
Beyond these examples, it is notable that Seq2seq models can also be used for syntactic parsing, where the task is to generate a syntactic tree for a sentence. By representing this tree as a sequence, it too becomes suitable for Seq2seq processing. Additionally, tasks such as multi-label classification and object detection can be approached with Seq2seq models.
The Seq2seq model is traditionally composed of an encoder and a decoder. This architecture was first introduced in the paper Sequence to Sequence Learning with Neural Networks in September 2014, with the Transformer model now being the most well-known Seq2seq variant.
Encoder
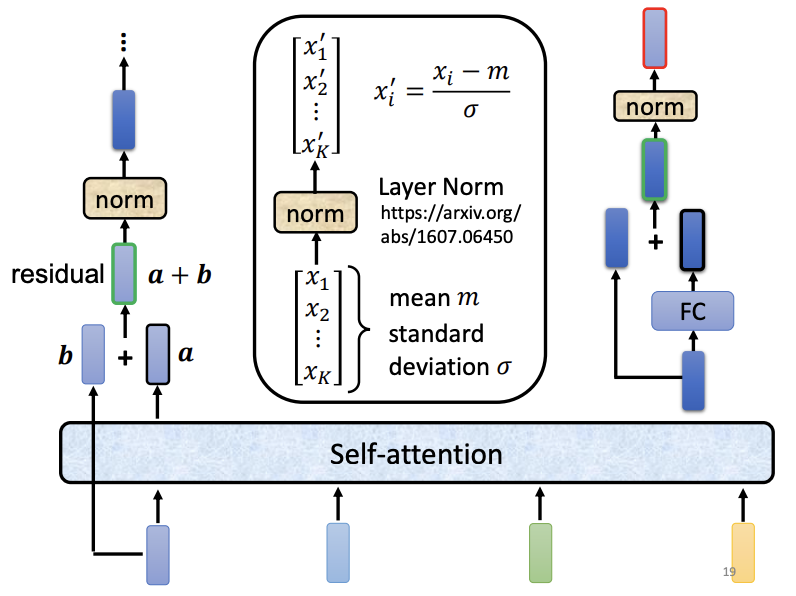
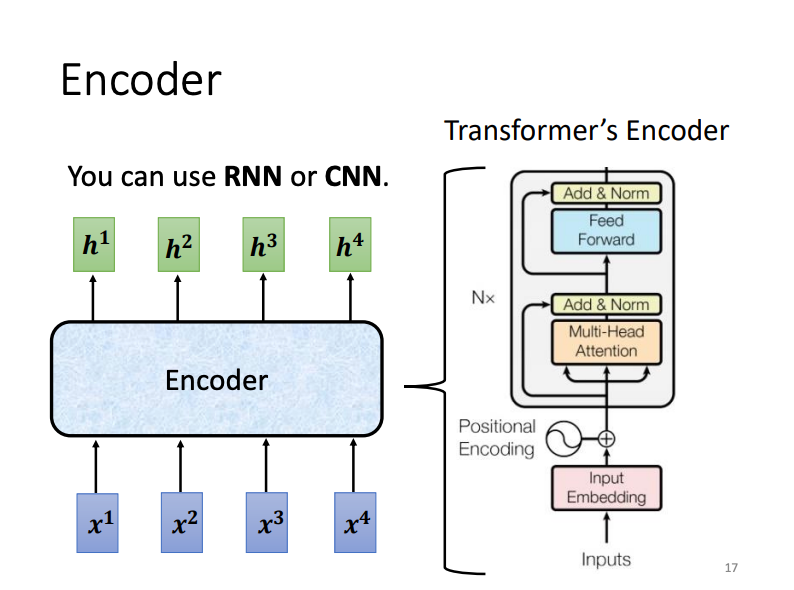
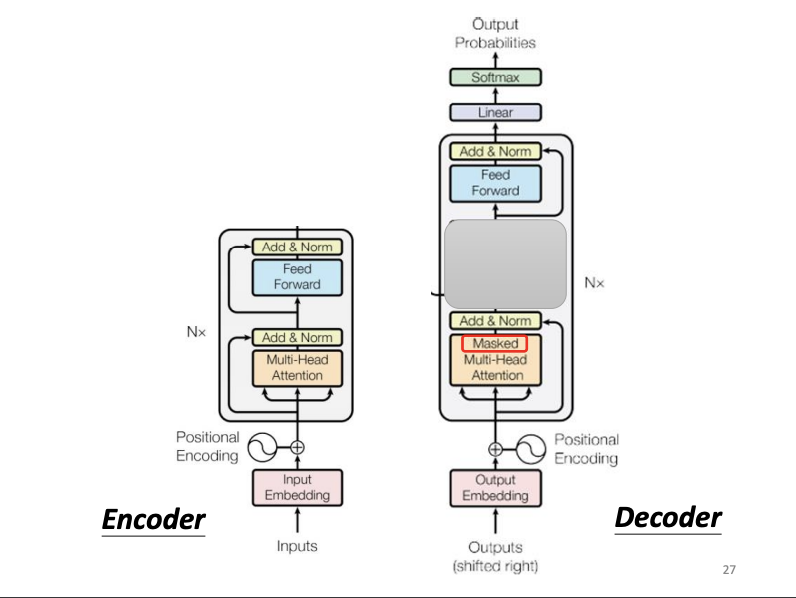
The encoder processes an input sequence of vectors and outputs a transformed sequence of vectors. Various architectures exist for this purpose, but the Transformer architecture specifically leverages Self-Attention. Unlike simple Self-Attention, the Transformer incorporates a residual connection, which combines the output vector with the original input to create a more robust representation. Following this, layer normalization is applied to standardize the residual vector’s values. This normalized vector is then passed through a fully connected network, again combined with a residual connection. A final layer normalization completes the encoder’s output.
In the complete Transformer encoder architecture, positional encoding is first applied to the input vector to encode the sequential order of tokens. Then, multi-head self-attention layers and Add & Norm operations (residual connection with layer normalization) are applied, followed by a feed-forward network and additional Add & Norm operations.
Decoder
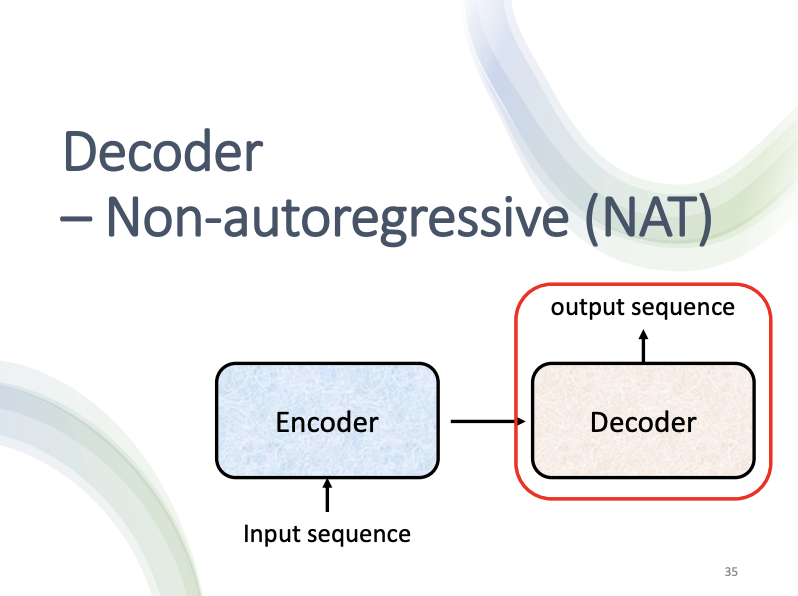
There are two primary types of decoders, auto-regressive and non-auto-regressive.
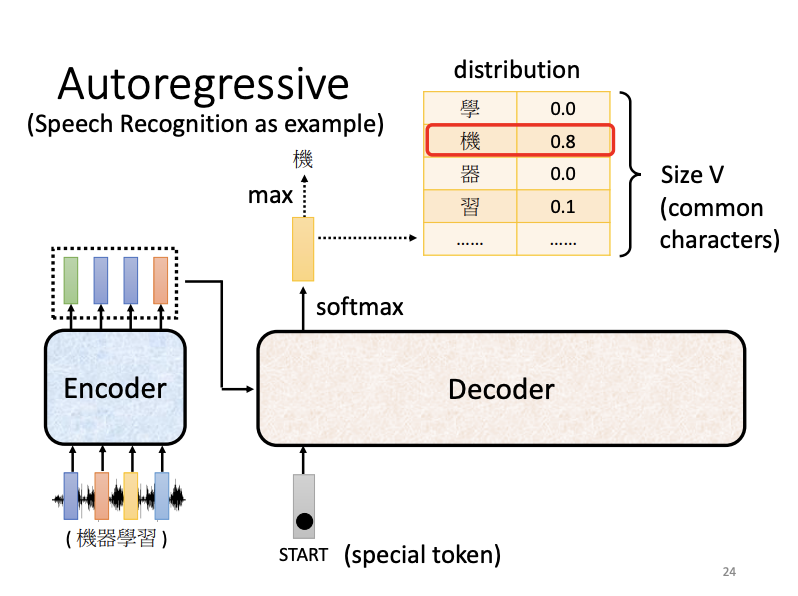
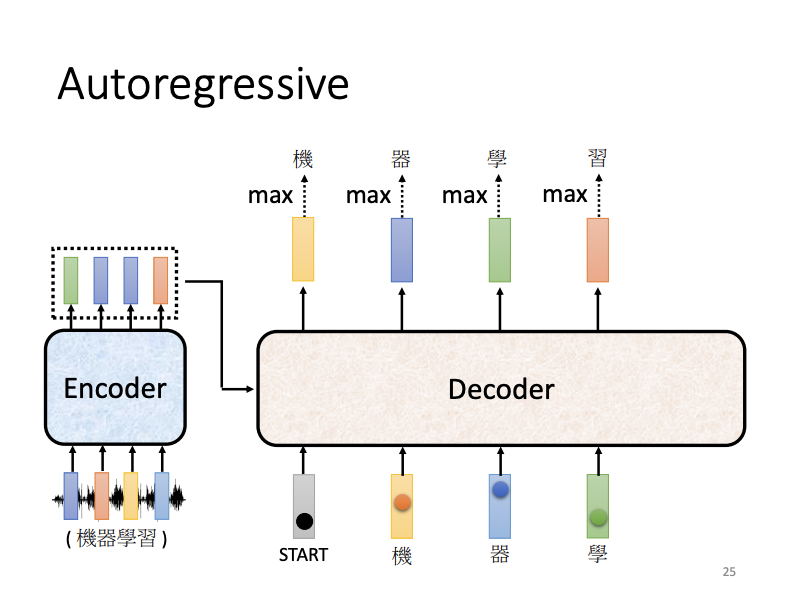
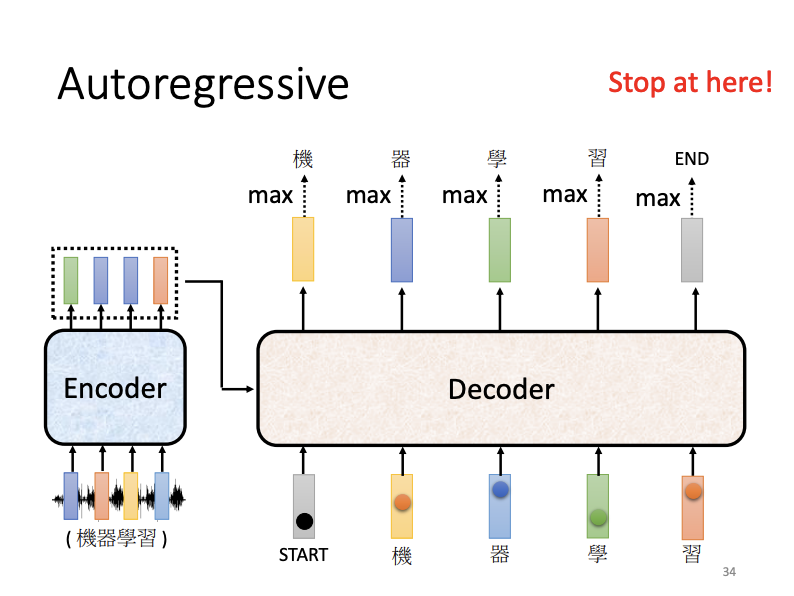
In auto-regressive decoding, as applied in speech recognition, the encoder processes an audio sequence, outputting a vector sequence that is subsequently fed into the decoder. Along with this, the decoder receives tokens, such as a BEGIN token. When fed with the BEGIN token, the decoder produces a one-hot vector, which is then transformed into a probability distribution through the soft-max function. The word with the highest score in this distribution is selected as the output. This output word, in vector format, is then fed back into the decoder to predict the next word, producing a sentence token-by-token in sequence.
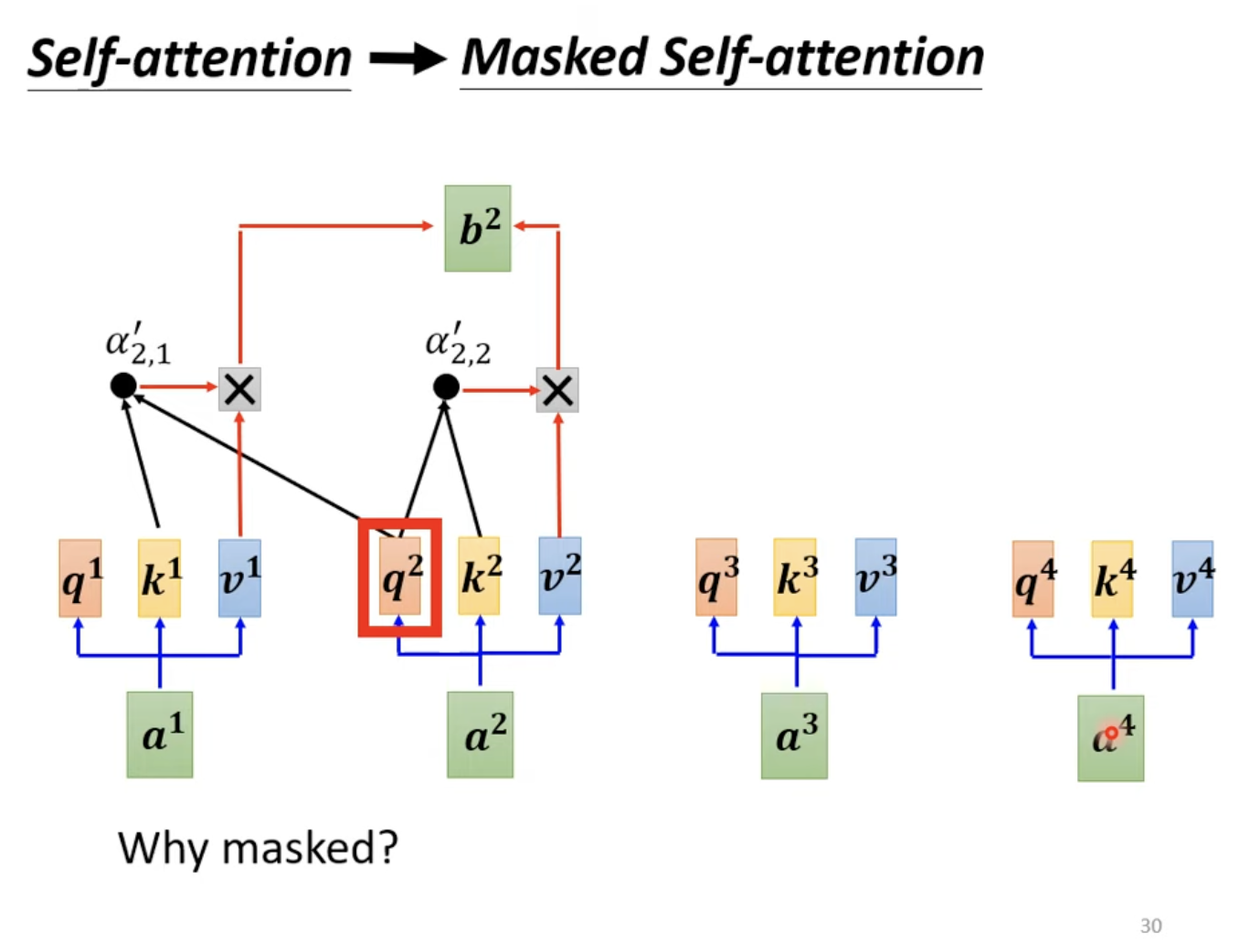
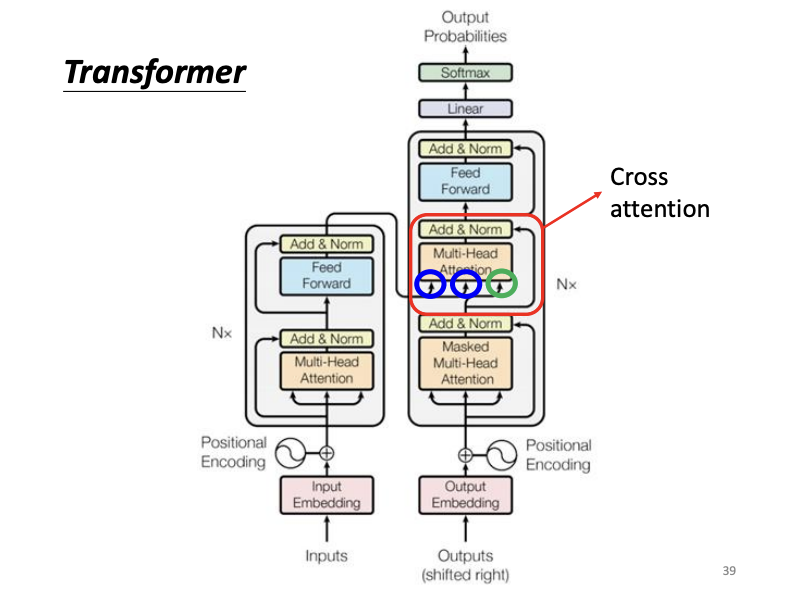
The encoder and decoder share structural similarities: both begin with positional encoding, followed by multi-head self-attention, Add & Norm layers, feed-forward networks, and further Add & Norm layers. The key difference in the decoder lies in the use of masked multi-head self-attention. This self-attention mechanism allows each output vector to consider only the preceding input vectors and the current one, in result making output tokens generated sequentially.
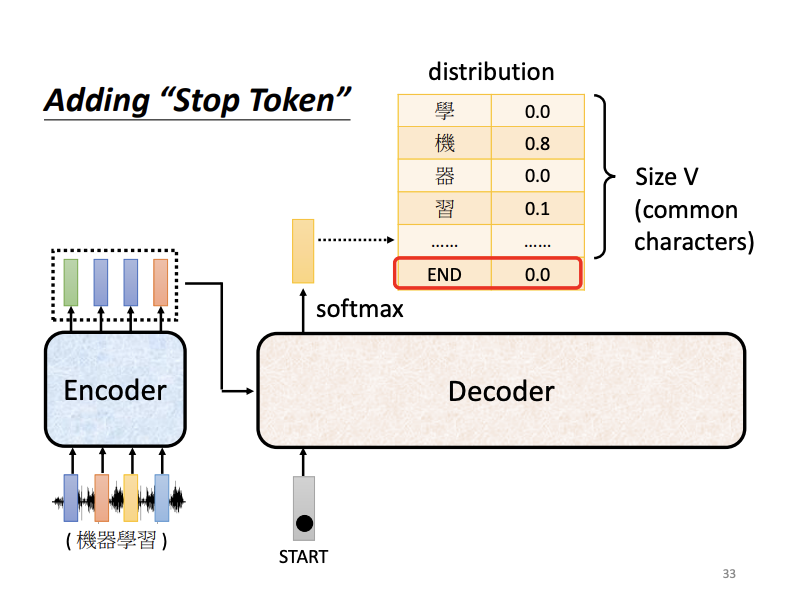
Another important task is that the decoder need to determine the length of the generated sentence and recognize when to stop. This is achieved by training the decoder to recognize a special END token, which signals the completion of the sequence.
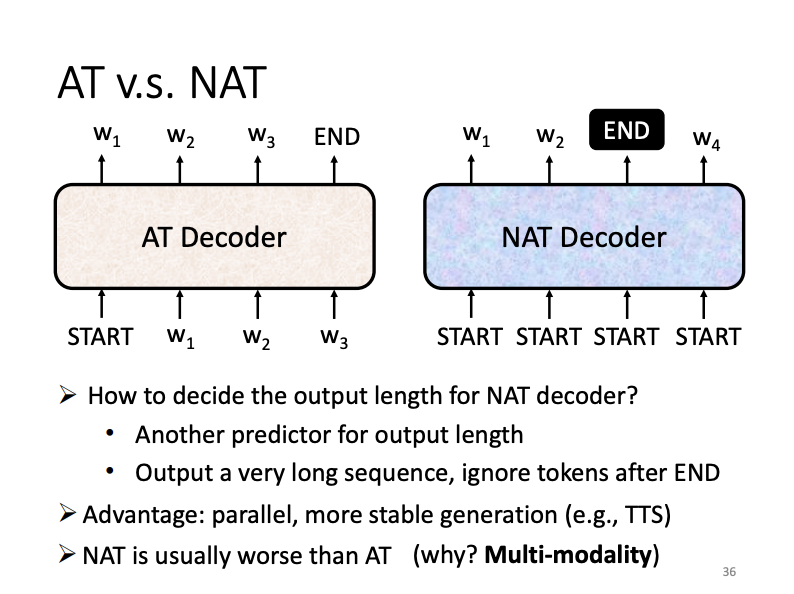
What an auto-regressive decoder does is that it generates output vectors based on all previously generated output vectors, processing them one-by-one. In contrast, a non-auto-regressive (NAT) decoder generates all output vectors simultaneously from the entire set of input vectors, which facilitates parallel processing and simplifies output length control, although it may underperform compared to the auto-regressive approach.
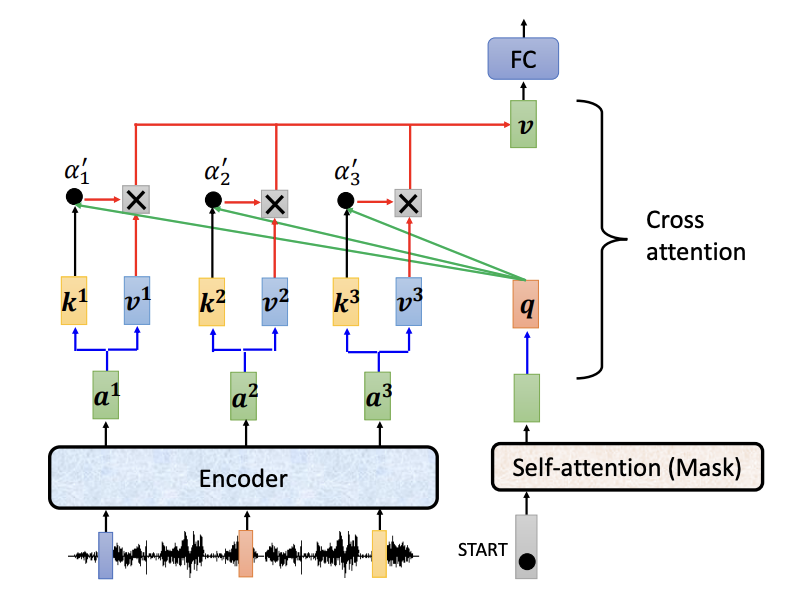
Between the encoder and decoder lies an essential component known as cross-attention, where the decoder’s query vectors interact with the key and value vectors from the encoder. This cross-attention mechanism enables the model to align and generate a final output vector by linking the encoder and decoder representations.
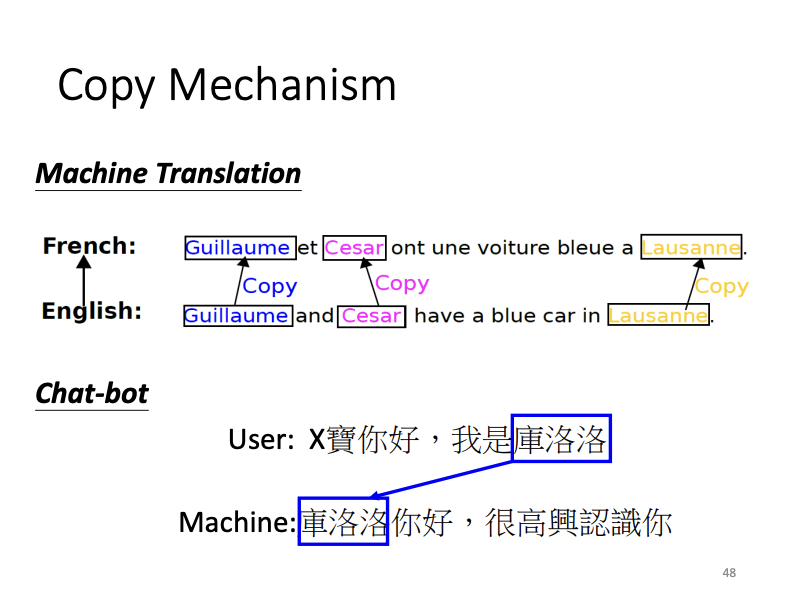
- Copy Mechanism
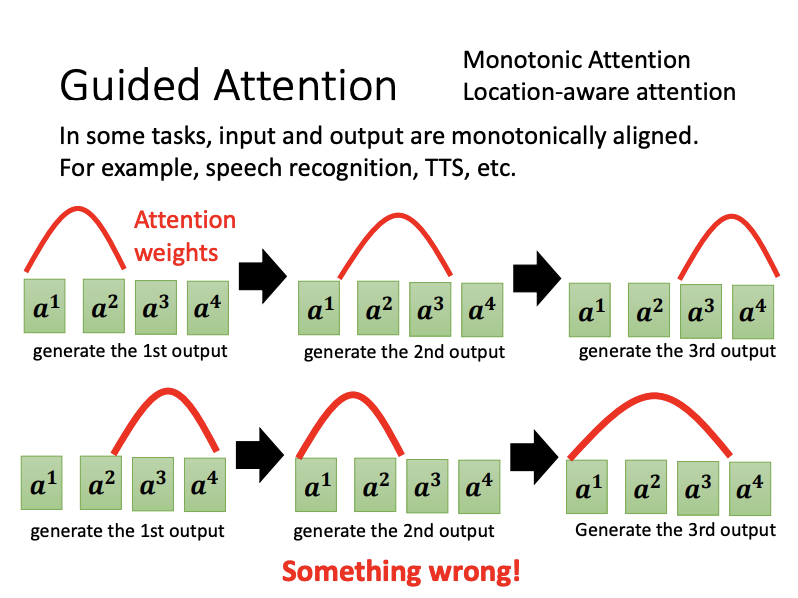
- Guided Attention
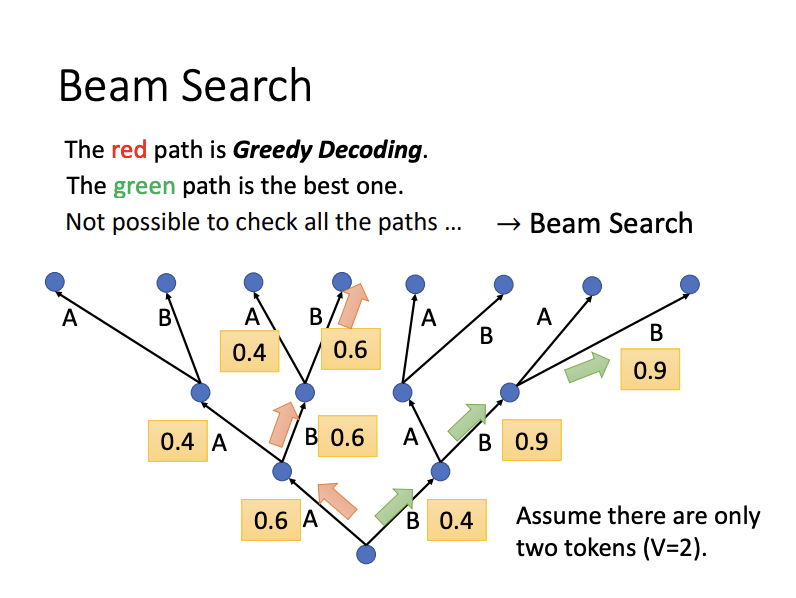
- Beam Search
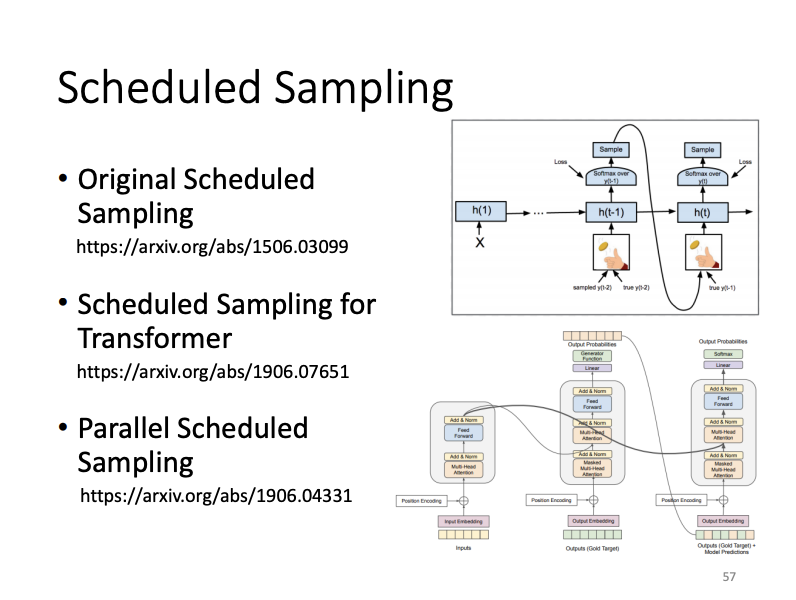
- Scheduled Sampling
![[ML]Transformer: Attention is All You Need](/assets/images/2024-09-27-Transformer/2024-10-25-23-26-37.png)