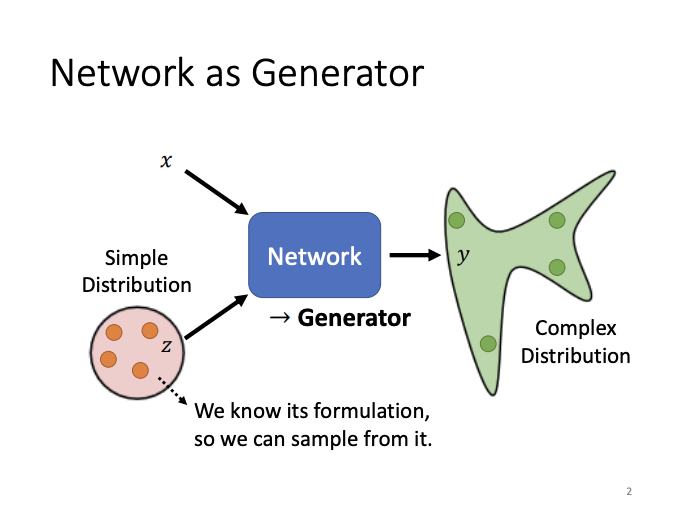
It’s common for neural networks to output values, vectors, or sequences for tasks such as classification or regression. Beyond this, networks can also be designed as generators to produce generative outputs. Unlike typical neural networks, a generative network receives not only an input but also a random value sampled from a simple distribution. What is unique about generative networks is that, unlike conventional networks where a consistent input always results in a fixed output, the generator can produce varied outputs from the same input due to the incorporation of the random component. This randomness results in a complex output distribution.
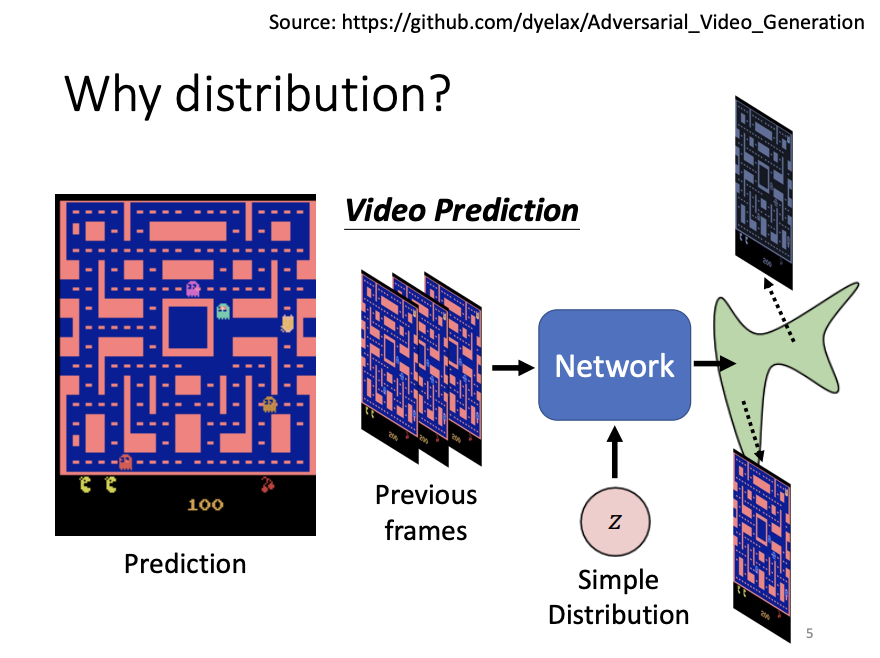
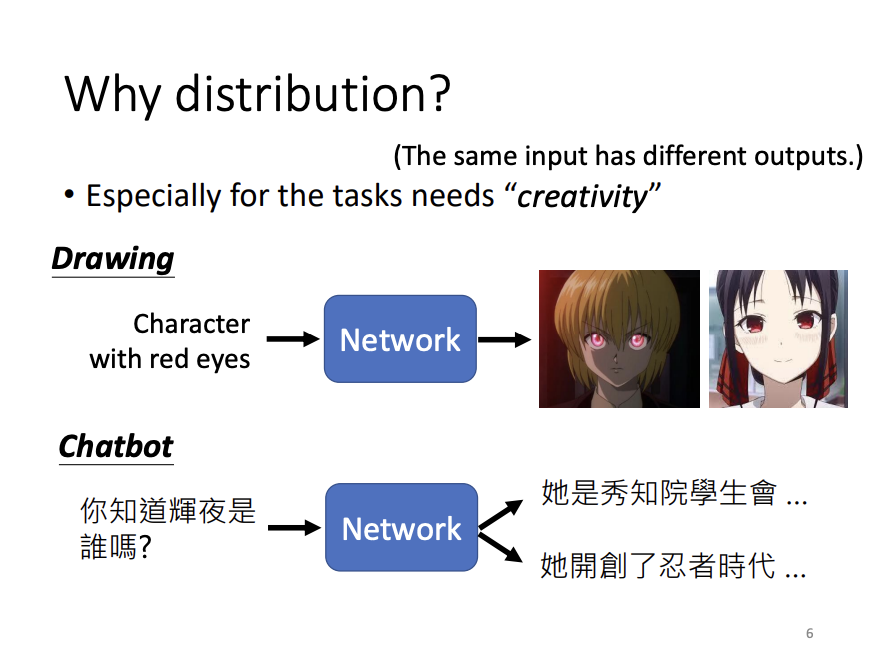
For tasks that require creativity, such as video prediction, artwork generation, or conversational agents, generative networks are a suitable choice. Among all the generative networks, the generative adversarial network (GAN) is one of the most well-known models.
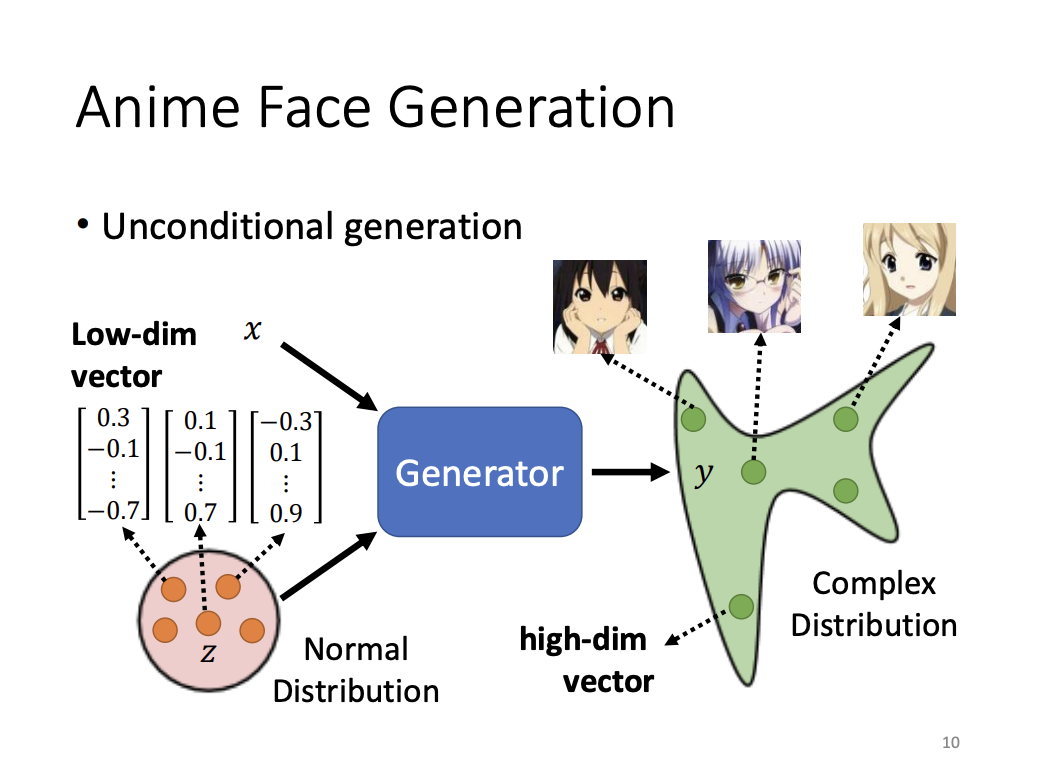
Generative models can be categorized into conditional and unconditional generation, depending on whether an input vector is fed into the network alongside the random component. In unconditional generation, such as in anime face generation, the generator receives a low-dimensional vector sampled from a standard distribution and outputs a high-dimensional vector representing an image. This process collectively forms a complex distribution that captures a wide range of possible outputs.
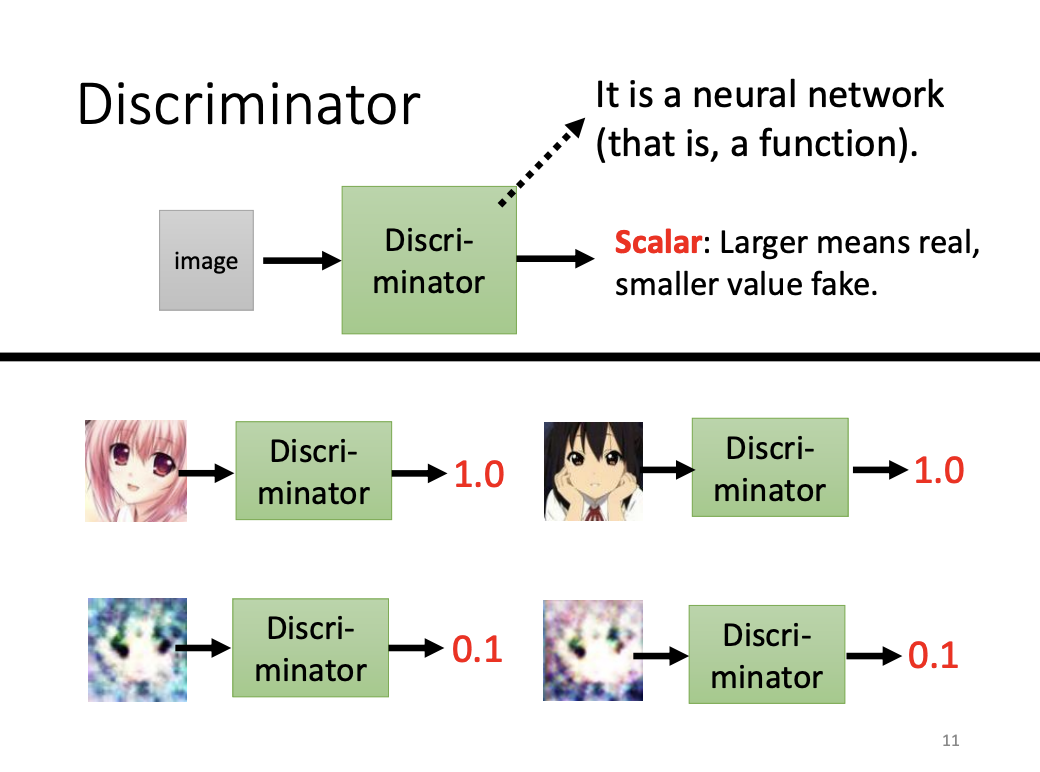
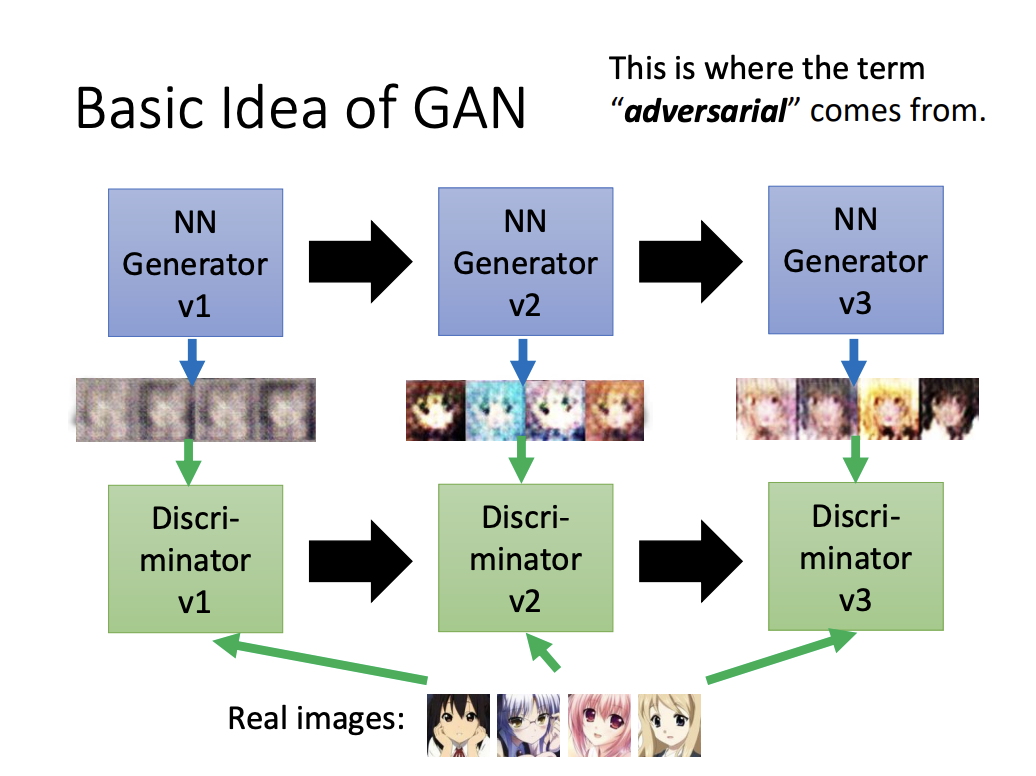
Apart from the generator, another key component of GAN is the discriminator, which is also a neural network. The discriminator outputs a score representing the similarity between generated images and real images. The core idea of GANs is to use the discriminator to evaluate the quality of the generator’s output. Meanwhile, the generator aims to “fool” the discriminator by producing increasingly realistic samples over iterations, resulting in improved performance through an adversarial training process.
The images below illustrate the progression of GAN-generated samples:
- Anime face generation at 100 updates, 2000 updates, and 50000 updates.
- Examples of models: StyleGAN, Progressive GAN, and BigGAN.
Divergence
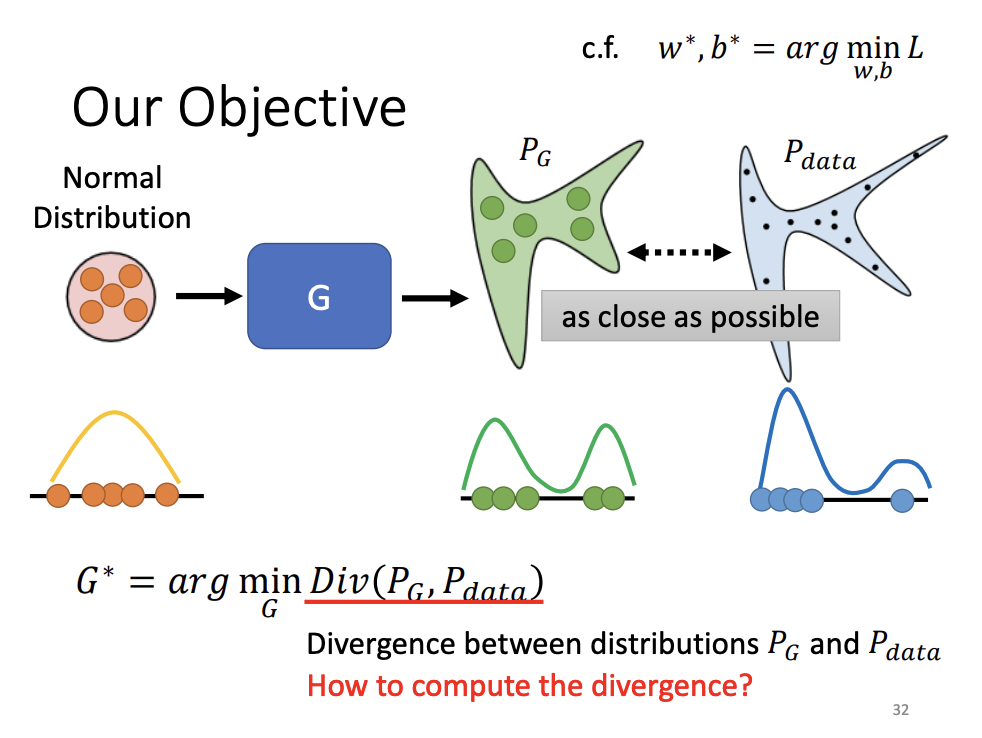
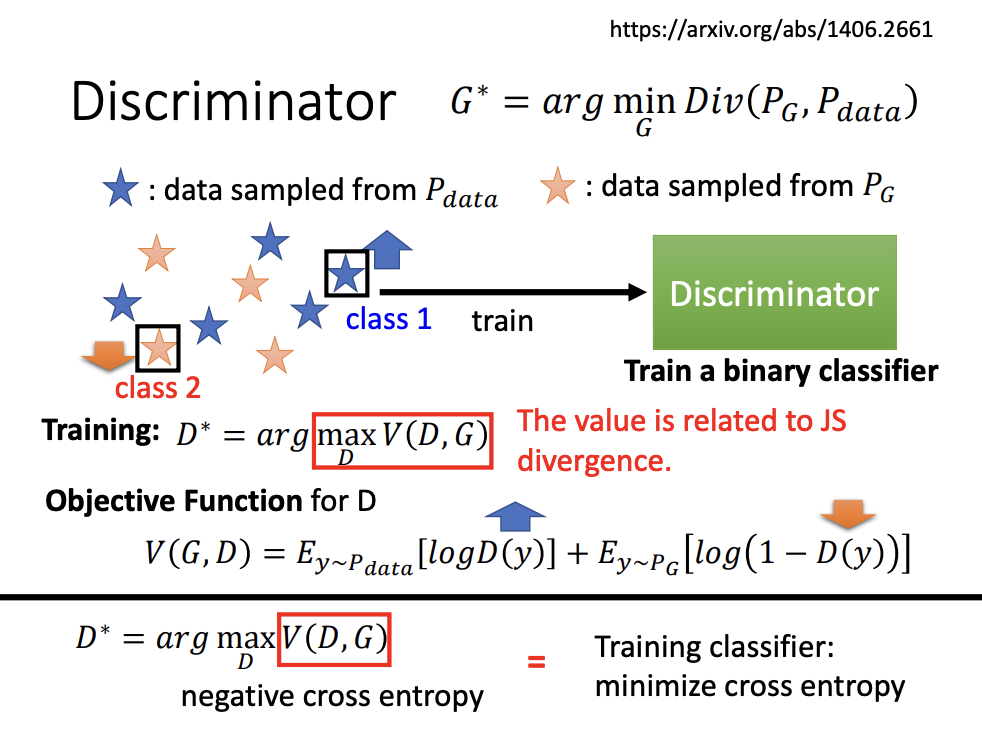
The goal of the generator is to make the generated distribution as close as possible to the real data distribution, minimizing divergence. However, directly computing the divergence between two complex distributions is challenging. GANs address this by sampling data from both distributions and estimating divergence based on these samples. The discriminator acts as a binary classifier, trained to distinguish between real and generated samples.
The discriminator’s task can be seen as a form of binary classification. When the generated samples closely resemble those from the real data, the loss function of the classifier becomes difficult to minimize, which indirectly indicates a smaller divergence. Conversely, a higher loss value suggests a greater divergence between the two distributions.
The original GAN employs Jensen-Shannon (JS) divergence to measure the difference between the generated and real data distributions. However, JS divergence has limitations, especially when the two distributions do not overlap. In such cases, the JS divergence is always log2, regardless of how close the distributions might actually be. This issue makes optimization challenging during training.
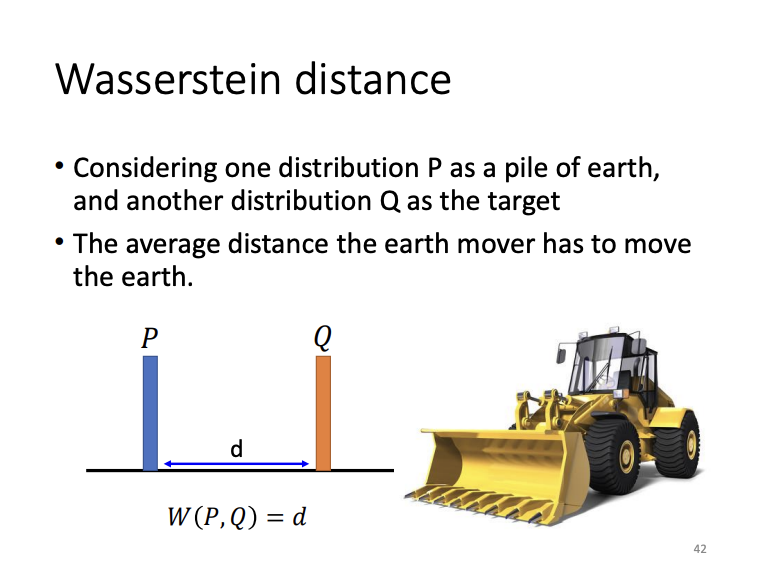
WGAN
To address the limitations of JS divergence, Wasserstein GAN (WGAN) introduces the Wasserstein distance, which measures the “cost” of transforming one distribution into another. Unlike JS divergence, Wasserstein distance can effectively differentiate between non-overlapping distributions, enabling more stable training and guiding the model toward better convergence.
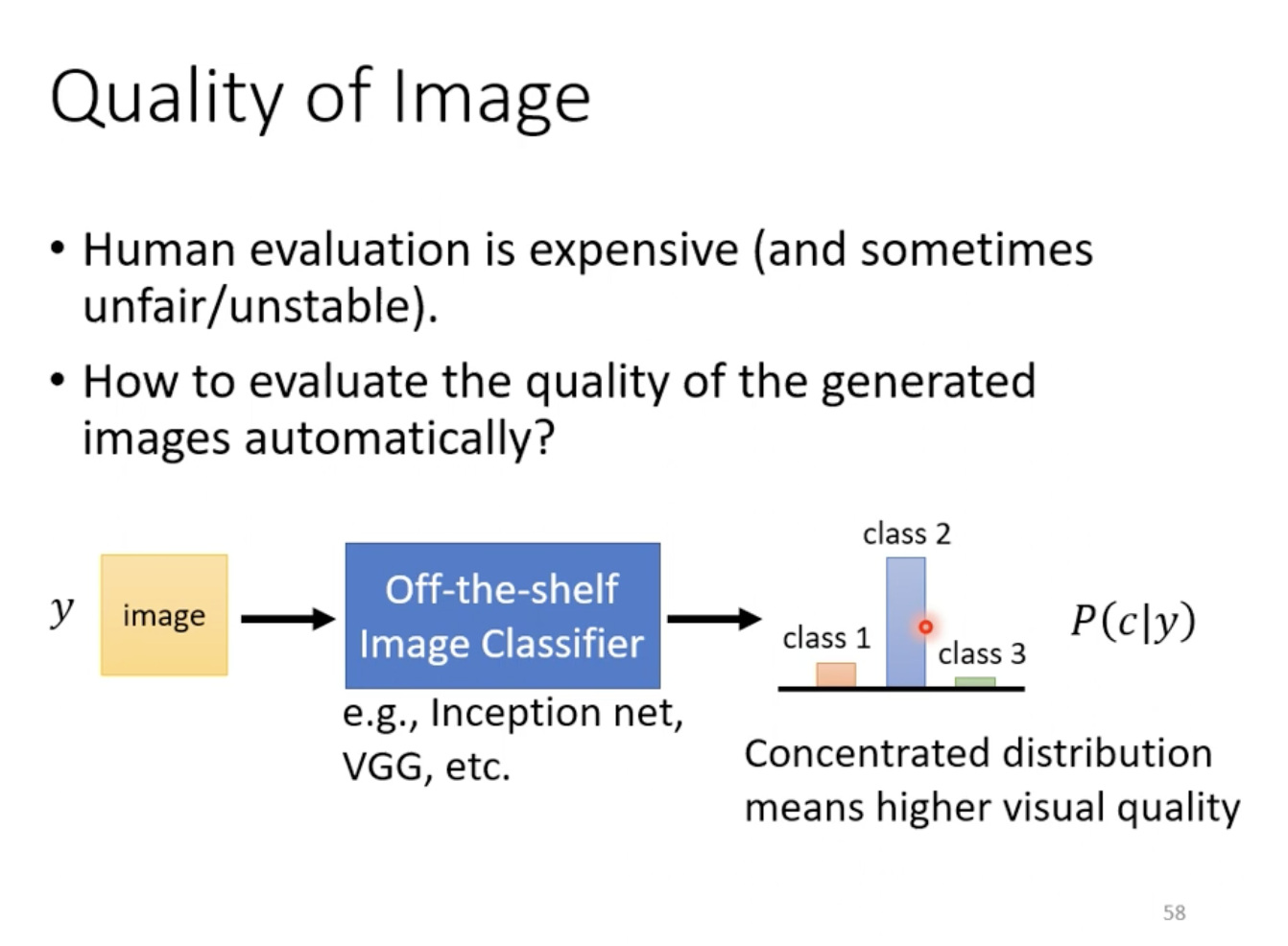
Image Quality
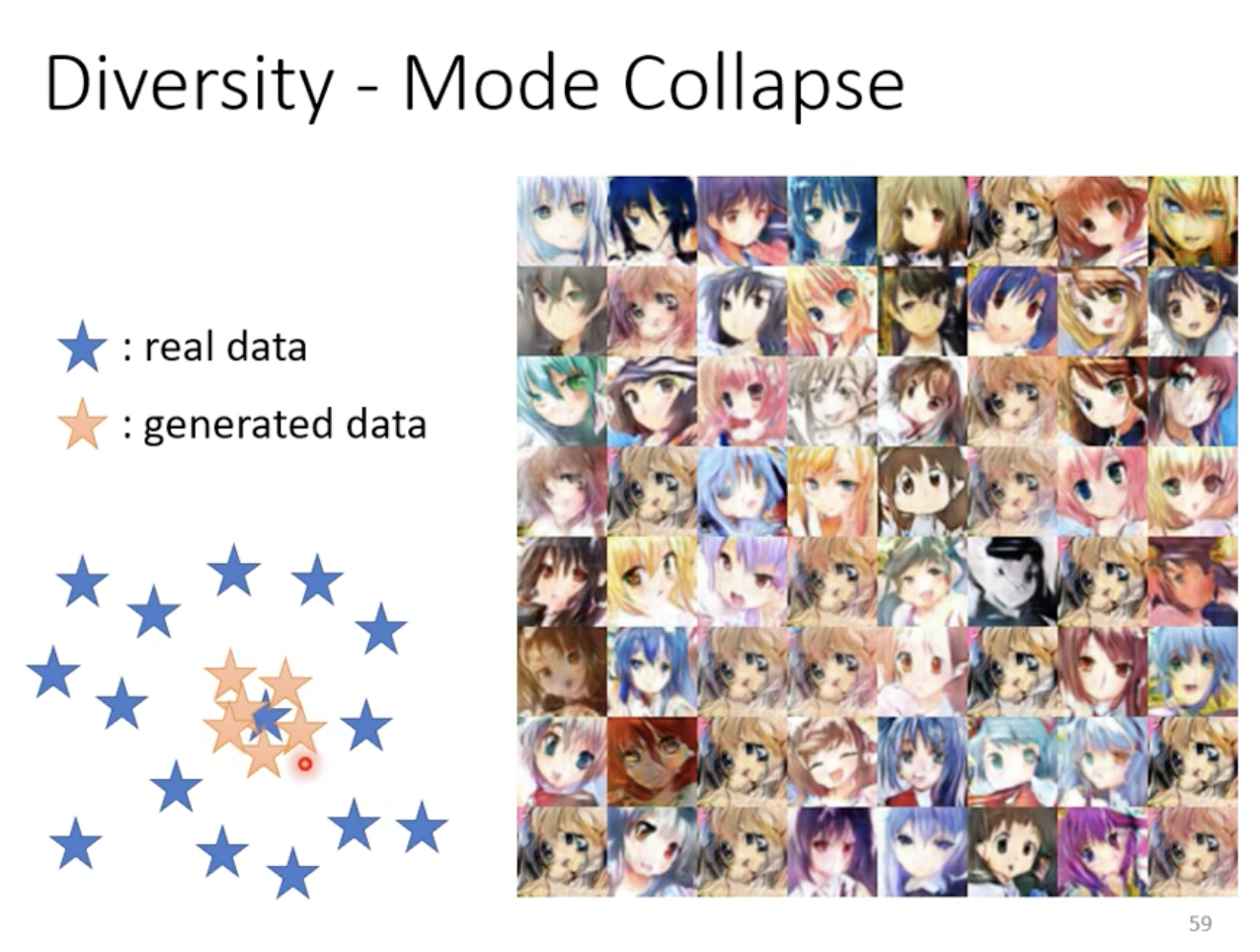
Assessing the quality of GAN-generated images through human evaluation is costly, and usually automated methods are preferred. One approach is to use an image classifier to evaluate the generated images. If the output distribution of the classifier is concentrated, it indicates higher visual quality. However, this method does not address the problem of mode collapse, where the generator produces limited variations of the same image. In practice, when encountering mode collapse, the model version prior to the collapse is often used to mitigate the issue. Another related problem is mode dropping, where the generated distribution fails to cover certain parts of the real distribution, even though diversity is seemingly maintained.
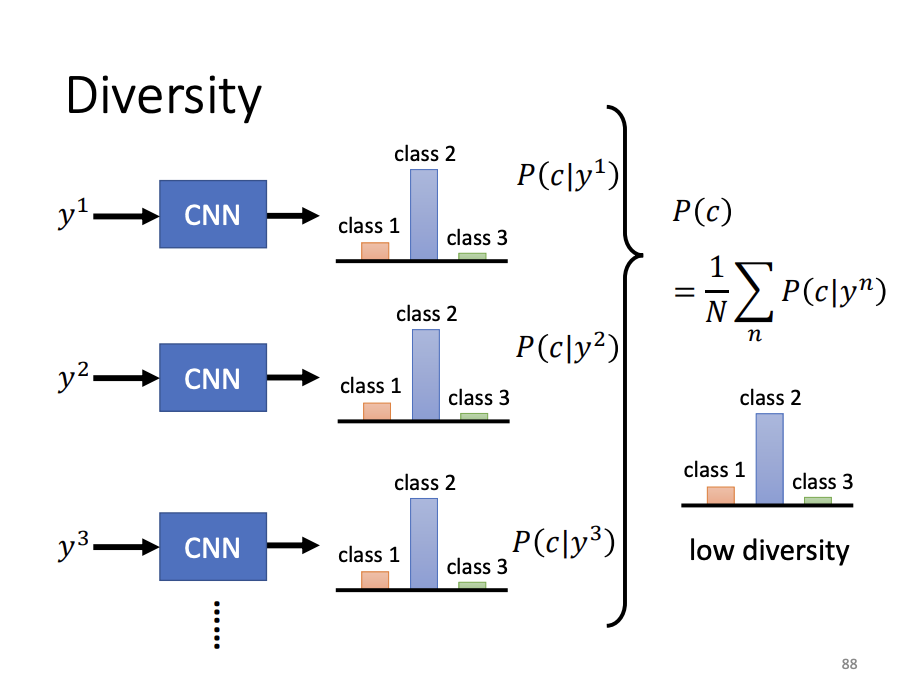
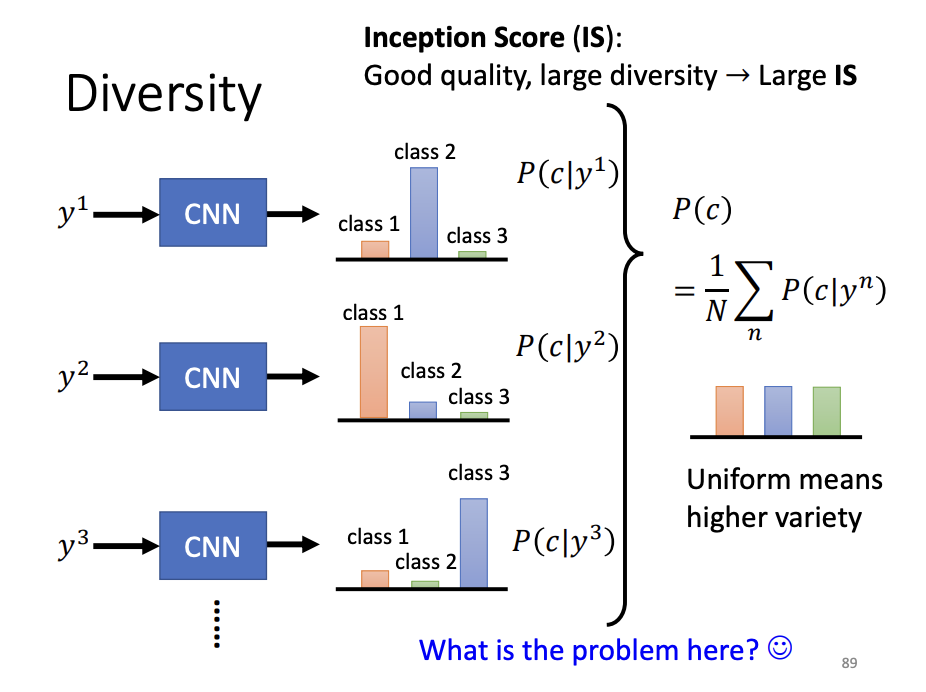
Diversity
To evaluate the diversity of GAN-generated images, an image classifier can be employed to classify each generated image, and the resulting distributions are averaged. If the averaged distribution is concentrated, it suggests insufficient diversity in the generated samples.
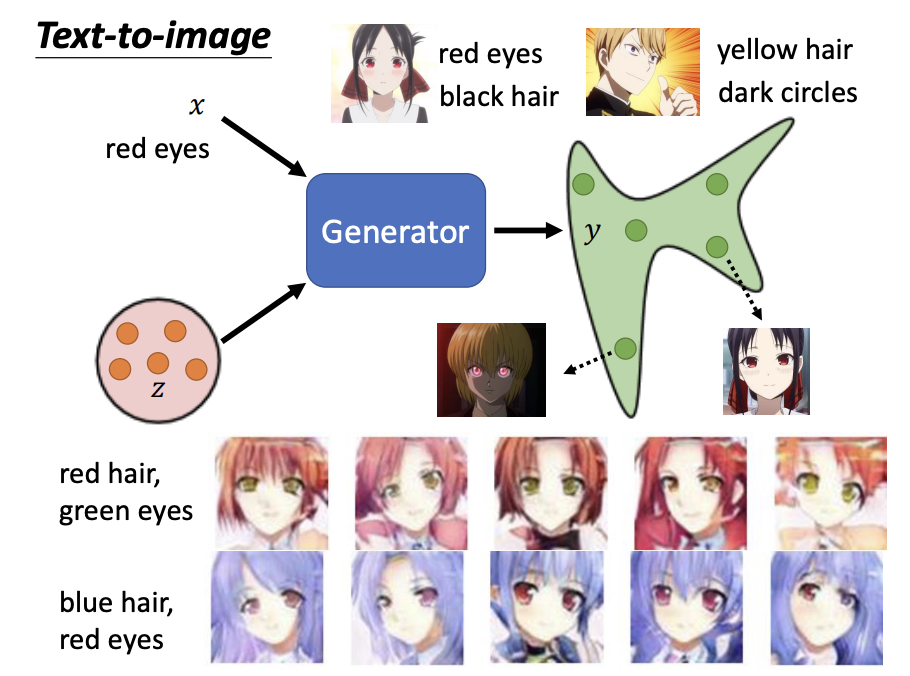
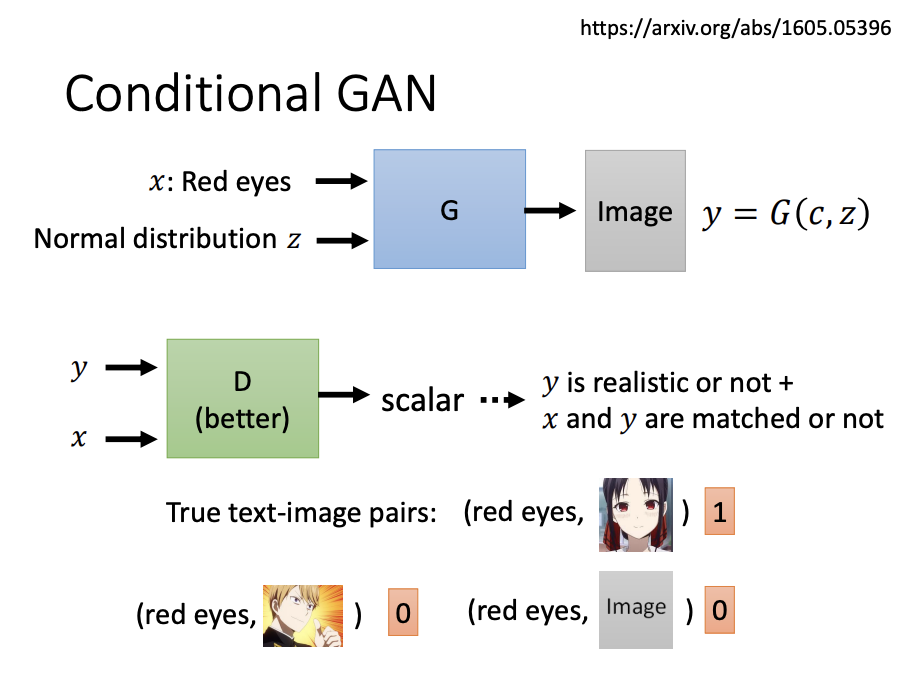
Conditional Generator
The primary difference between conditional and unconditional generators is that conditional generators receive both a random input and a conditional input value. One example is text-to-image generation. During the training of a text-to-image discriminator, both the image and the corresponding conditional input are fed into the network.
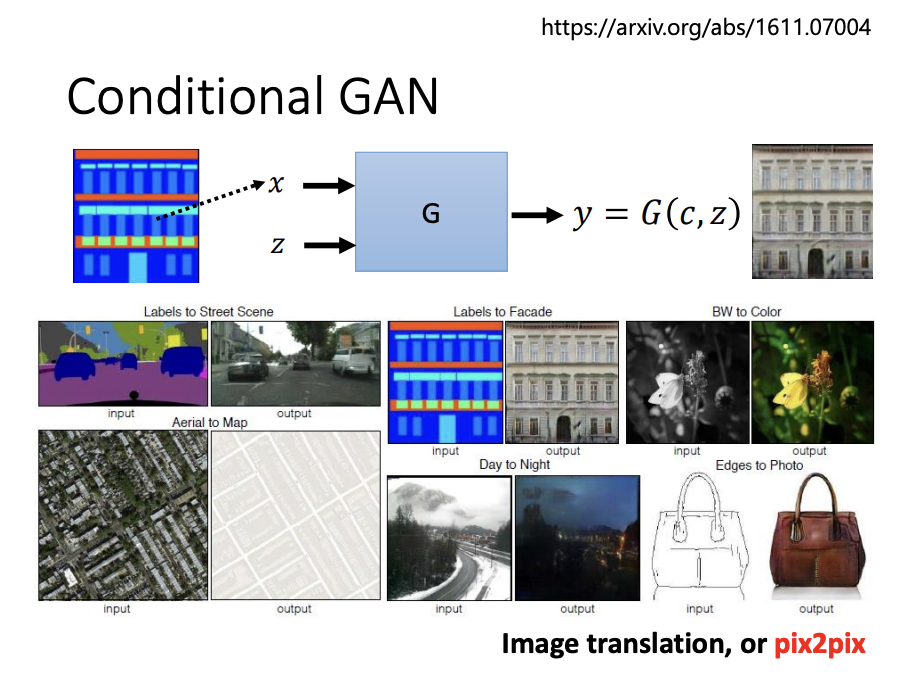
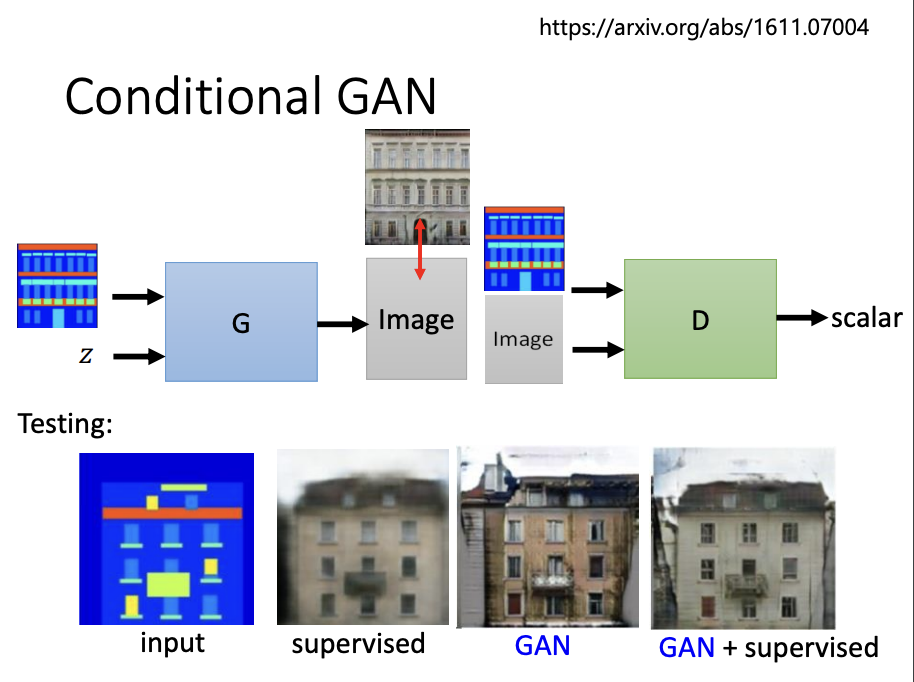
Image translation is another example of a conditional GAN, where the model receives an input image and generates a translated version of it. Compared to supervised learning, conditional GANs can produce more realistic images due to the adversarial feedback from the discriminator. However, this can sometimes result in overly creative outputs, generating unexpected elements. For optimal performance, a combination of conditional GAN and supervised learning is often employed.
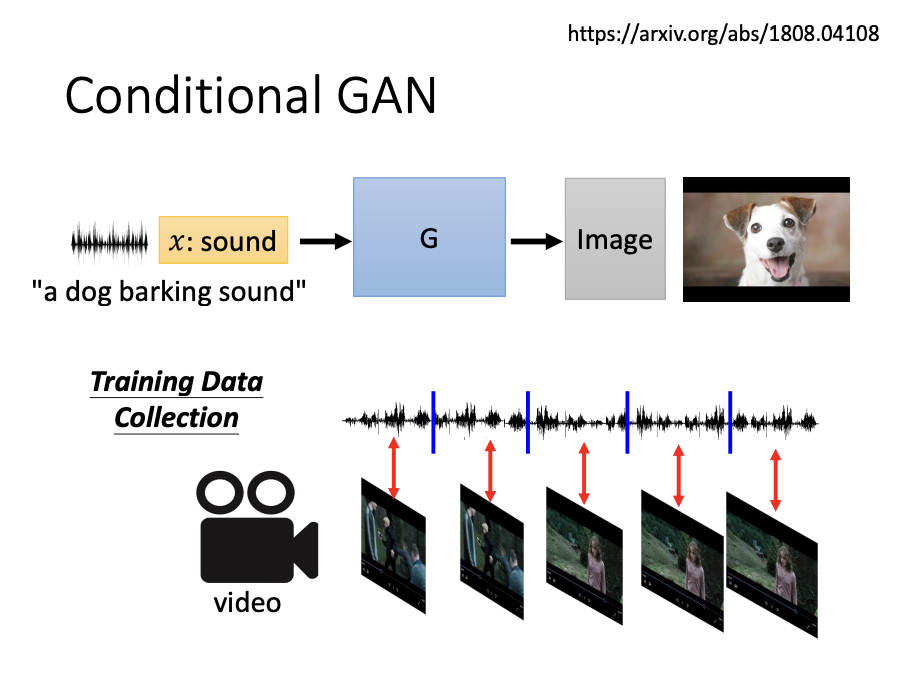
Sound-to-image synthesis is also an example of a conditional GAN application.
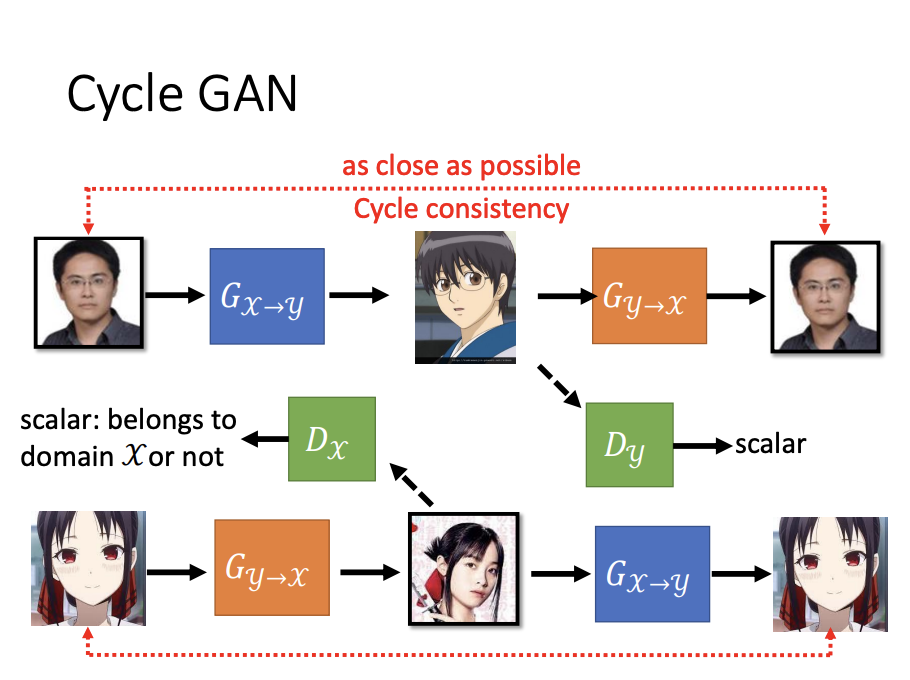
Cycle GAN
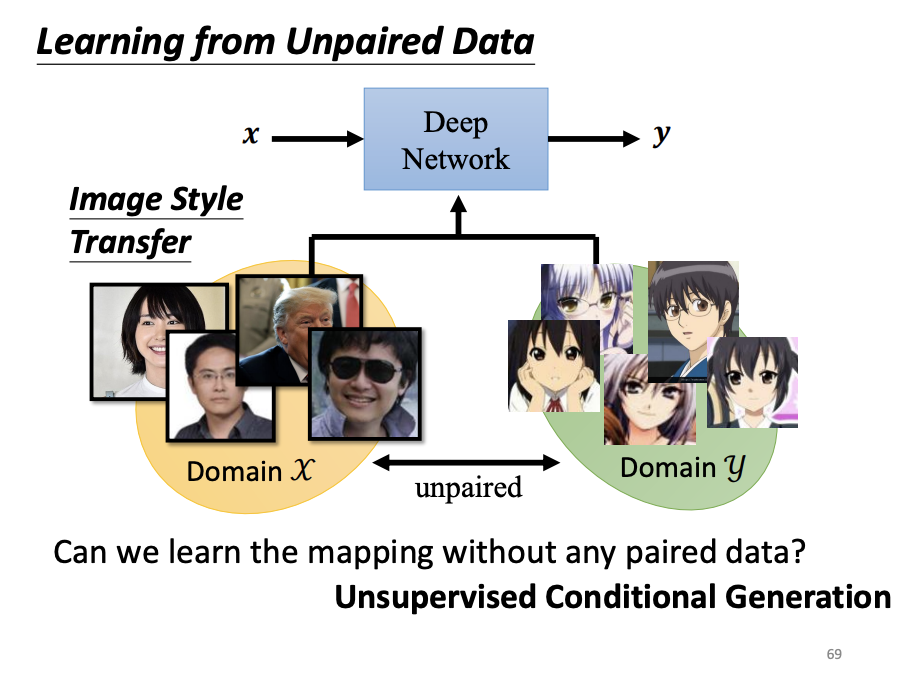
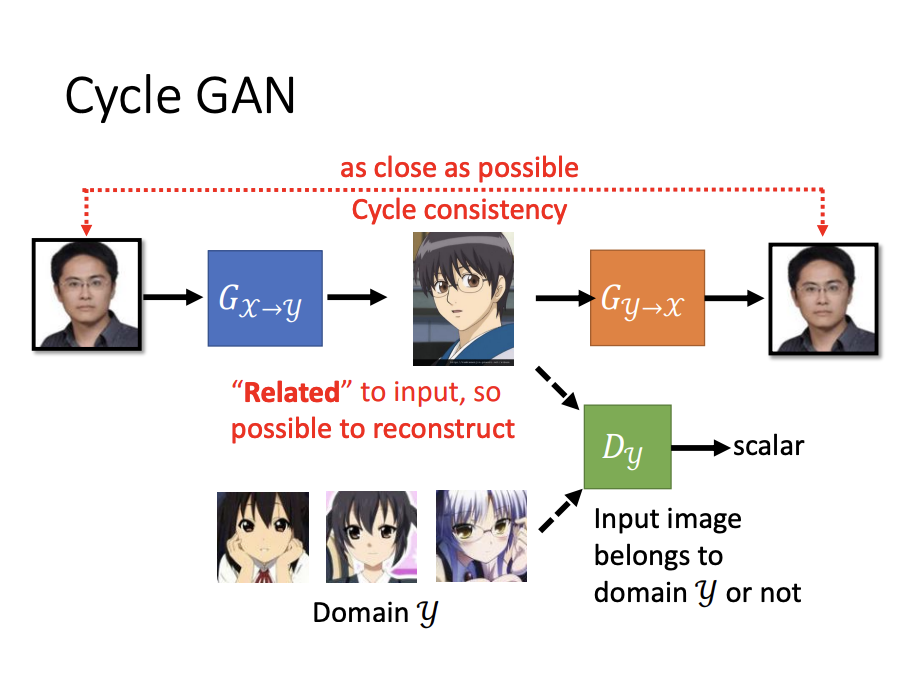
For tasks involving unpaired data, such as image style transfer, CycleGAN is a suitable choice. Unlike traditional GANs, CycleGAN introduces a second generator that transforms the generated image back to the original image. This forces the first generator to consider the input image during generation, ensuring that the output can be successfully reverted. To train the second generator, an additional discriminator is also introduced. Together, two generators and two discriminators form the CycleGAN architecture.
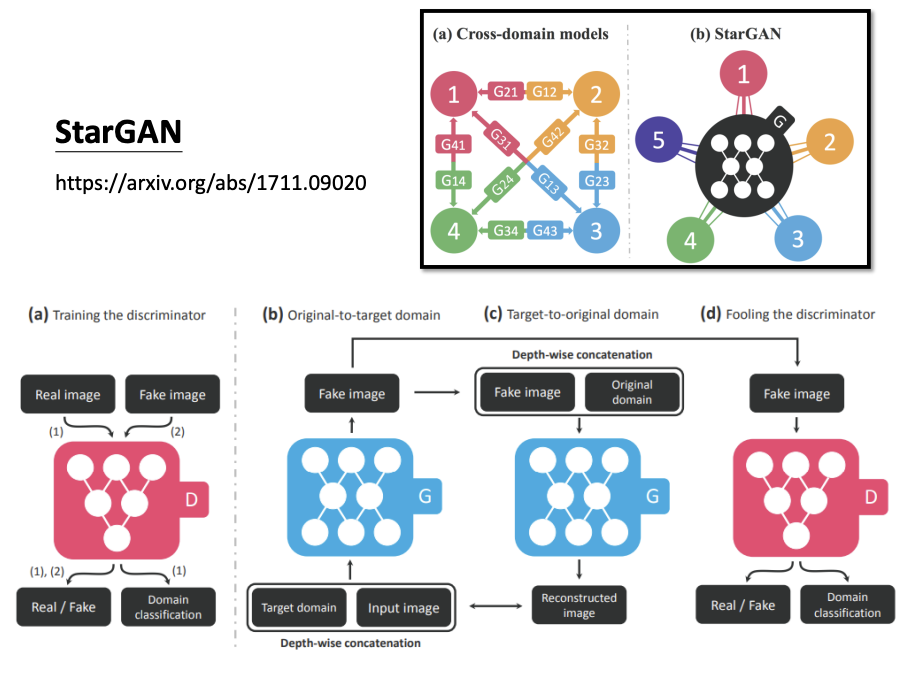
CycleGAN is effective for style transfer between two distinct domains. For tasks involving multiple styles, StarGAN is a more versatile option.
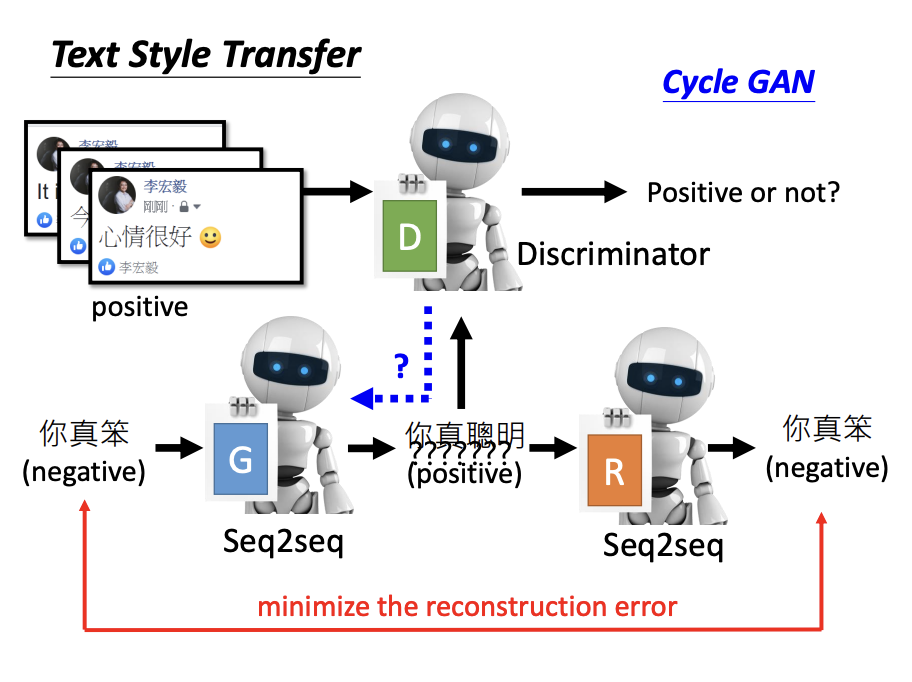
Beyond image style transfer, CycleGAN can also be applied to tasks such as text style transfer.
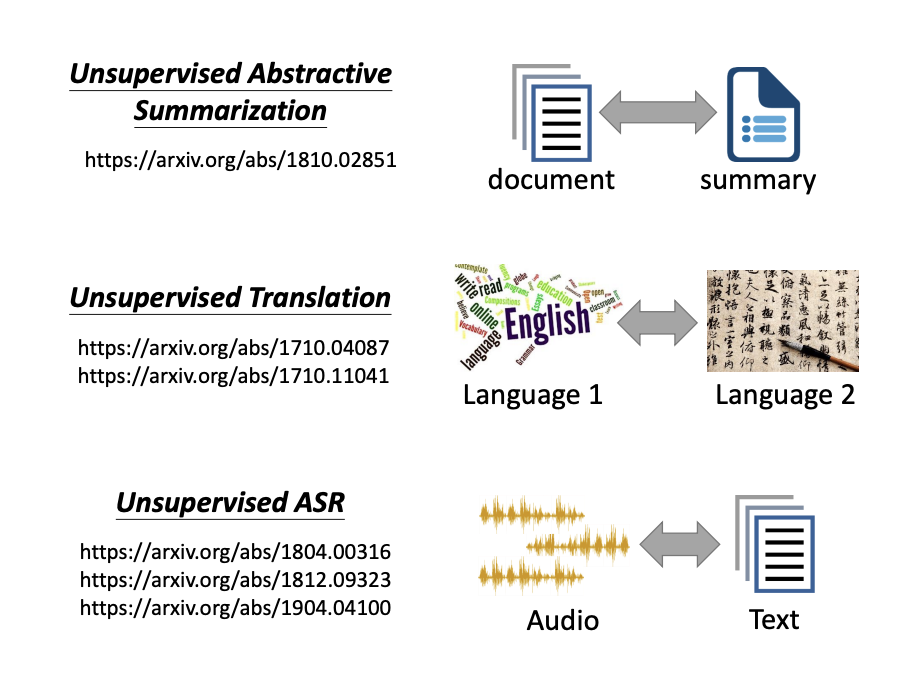
In unsupervised learning, similar techniques can be applied to tasks like unsupervised abstractive summarization, unsupervised translation, and unsupervised automatic speech recognition (ASR).
![[ML]Generative Adversarial Network](/assets/images/2024-10-27-GAN/2024-11-09-01-08-25.png)